
Введение
Этот документ является продолжением обсуждения вероятностных методов
в машинном обучении. Мы рассмотрим классический и не утративший своего значения метод
n-грамм для прогнозирования последовательностей.
В качестве примера таких последовательностей будут рассмотрены буквы и слова текстов на ествественном
языке. Однако, этот же подход с небольшими модификациями можно использовать при анализе временных
рядов и в других задачах.
Приведенные далее примеры на Python используют библиотеку nltk (Natural Language Toolkit)
и могут быть найдены в файле ML_NGrams.ipynb.
Рассмотрен также существенно более быстрый модуль my_ngrams.py,
основанный на древесном представлении n-грамм.
Обзор Google Ngram Viewer: для чего нужен сервис, как работает и как пользоваться?
Google Ngram Viewer – это интересный инструмент поиска повторений необходимых слов или словосочетаний, имен известных личностей, дат и многого другого. Программа рассчитана на поиск повторений в интернете. Данная визуализация повторений может быть полезна для какого-либо исследования, как помощник в реализации проекта, для выполнения филологического задания и в других видах деятельности.
Как работает Google Ngram Viewer?
Программе необходимо задать критерий поиска, после чего система начинает искать и анализировать подобные слова и выражения в печатных источниках сервиса Гугл. В базе имеется несколько миллионов томов, начиная с 16 века. Реализован поиск на нескольких языках, включая русский.
Найденные повторения отображаются на экране монитора пользователя в виде графика. Если в поиске было указано несколько слов, то каждый график будет иметь свой цвет, а над ним будет представлена расшифровка цветов.
Как запустить процедуру поиска?
- Необходимо зайти в онлайн-сервис Ngram Viewer.
- В верхней строке «Graph these comma-separated phrases» (напишите избранные фразы через запятую) внести искомые слова или словосочетания.
- Затем в диалоговой строке «between» (период) следует поставить требуемые года поиска.
- Далее пользователю предлагают указать язык, на котором следует анализировать произведения.
- После чего можно выставить временную погрешность в годах и нажать на кнопку поиска.
После выполненных манипуляций, на экране появится график частоты языковой единицы. А внизу под диаграммой будут представлены публикации, в которых были обнаружены требуемые фразы. Например, таким образом можно найти практически любую информацию. Щелкнув по временному периоду, откроется список произведений. Если есть необходимость, можно найти те материалы, из которых взята аналитика.
После завершения исследования в Google Ngram Viewer можно поделиться результатом напрямую в Tweet или скопировать ссылку и отправить другу.
части речи
Если слово включает в себя много частей речи, вы можете добавить текстовые операторы для уточнения. Правильные части слова в базе данных Google включают в себя все следующее:
- _ADJ_: прилагательное (быстрый, большой, умный)
- _ADV_: наречие (быстро, позже, всегда)
- _ПРОН_: местоимение (они, он, мы)
- _DET_: определение чего-то (a, an, the)
- _АДП_: (предлоги и послелоги)
- _NUM_: число (первое, второе и пятое)
- _CONJ_: спряжение (и, нет, но)
- _PRT_: Particle, редкий класс, редко используется для других словарных функций
Чтобы иметь сеть 5G, Google Stadia может потребоваться дополнительное оборудование для правильной работы.
Каждую из этих граммов можно объединить в утверждения. Например, «_ADJ_ мальчик», которое вернет прилагательное супруг + слова «мальчик».
Чтобы указать конкретную часть речи для одного поискового запроса, добавьте его в конец: что означает «water_VERB», без нижнего подчеркивания.
Чтобы включить каждую часть речи для данного слова, используйте оператор подстановки после подчеркивания, как показано ниже.
Тематическое исследование
Рассмотрим пример с уксусными пирогами. Они упоминаются в Лоре Ингаллс Уайлдерс Домик в прерии серии. Изучение с помощью веб-поиска Google, чтобы узнать больше о пирогах с уксусом, показывает, что они считаются частью американской южной кухни и действительно сделаны с уксусом
Они обращают внимание на времена, когда не у всех был доступ к свежим продуктам в любое время года, но так ли это на самом деле?
Поиск Google Ngram Viewer для пирог с уксусом, и вы встретите некоторые упоминания о пироге как в начале, так и в конце 1800-х годов, много упоминаний в 1940-х годах и растущее число упоминаний в последнее время. Однако с уровнем сглаживания 3 вы видите плато над упоминаниями 1800-х годов. Поскольку за это время было опубликовано не так много книг, и поскольку данные настроены на сглаживание, изображение искажается. Вероятно, только одна книга упоминала пирог с уксусом, и он был усреднен, чтобы избежать всплеска. Установив сглаживание на 0, вы можете видеть, что это именно тот случай. Пик сосредоточен в 1869 году, и есть еще один всплеск в 1897 и 1900 годах.
Маловероятно, что в остальное время никто не говорил о пирогах с уксусом: вероятно, повсюду распространялись рецепты, но люди не писали о них в книгах, и это важное ограничение поисков Ngram
Corpora
Below are descriptions of the corpora that can be searched with the
Google Books Ngram Viewer. All corpora were generated in July
2009, July 2012, and February 2020; we will update these corpora as our book
scanning continues, and the updated versions will have distinct persistent
identifiers. Books with low OCR quality and serials were excluded.
Informal corpus name
Shorthand
Persistent identifier
Description
American English 2019
eng_us_2019
googlebooks-eng-us-20200217
Books predominantly in the English language that were published in the United States.
American English 2012
eng_us_2012
googlebooks-eng-us-all-20120701
American English 2009
eng_us_2009
googlebooks-eng-us-all-20090715
British English 2019
eng_gb_2019
googlebooks-eng-gb-20200217
Books predominantly in the English language that were published in Great Britain.
British English 2012
eng_gb_2012
googlebooks-eng-gb-all-20120701
British English 2009
eng_gb_2009
googlebooks-eng-gb-all-20090715
English 2019
eng_2019
googlebooks-eng-20200217
Books predominantly in the English language published in any country.
English 2012
eng_2012
googlebooks-eng-all-20120701
English 2009
eng_2009
googlebooks-eng-all-20090715
English Fiction 2019
eng_fiction_2019
googlebooks-eng-fiction-20200217
Books predominantly in the English language that a library or publisher identified as fiction.
English Fiction 2012
eng_fiction_2012
googlebooks-eng-fiction-all-20120701
English Fiction 2009
eng_fiction_2009
googlebooks-eng-fiction-all-20090715
English One Million
eng_1m_2009
googlebooks-eng-1M-20090715
The «Google Million». All are in English with dates ranging from
1500 to 2008. No more than about 6000 books were chosen from any one
year, which means that all of the scanned books from early years are
present, and books from later years are randomly sampled. The random
samplings reflect the subject distributions for the year (so there are
more computer books in 2000 than 1980).
Chinese 2019
chi_sim_2019
googlebooks-chi-sim-20200217
Books predominantly in simplified Chinese script.
Chinese 2012
chi_sim_2012
googlebooks-chi-sim-all-20120701
Chinese 2009
chi_sim_2009
googlebooks-chi-sim-all-20090715
French 2019
fre_2019
googlebooks-fre-20200217
Books predominantly in the French language.
French 2012
fre_2012
googlebooks-fre-all-20120701
French 2009
fre_2009
googlebooks-fre-all-20090715
German 2019
ger_2019
googlebooks-ger-20200217
Books predominantly in the German language.
German 2012
ger_2012
googlebooks-ger-all-20120701
German 2009
ger_2009
googlebooks-ger-all-20090715
Hebrew 2019
heb_2019
googlebooks-heb-20200217
Books predominantly in the Hebrew language.
Hebrew 2012
heb_2012
googlebooks-heb-all-20120701
Hebrew 2009
heb_2009
googlebooks-heb-all-20090715
Spanish 2019
spa_2019
googlebooks-spa-20200217
Books predominantly in the Spanish language.
Spanish 2012
spa_2012
googlebooks-spa-all-20120701
Spanish 2009
spa_2009
googlebooks-spa-all-20090715
Russian 2019
rus_2019
googlebooks-rus-20200217
Books predominantly in the Russian language.
Russian 2012
rus_2012
googlebooks-rus-all-20120701
Russian 2009
rus_2009
googlebooks-rus-all-20090715
Italian 2019
ita_2019
googlebooks-ita-20200217
Books predominantly in the Italian language.
Italian 2012
ita_2012
googlebooks-ita-all-20120701
Compared to the 2009 versions, the 2012 and 2019 versions have
more books, improved OCR, improved library and publisher
metadata. The 2012 and 2019 versions also don’t form ngrams that cross sentence
boundaries, and do form ngrams across page boundaries, unlike the
2009 versions.
With the 2012 and 2019 corpora, the tokenization has improved as well, using
a set of manually devised rules (except for Chinese, where a
statistical system is used for segmentation). In the 2009 corpora,
tokenization was based simply on whitespace.
Как использовать инструмент просмотра Ngram в Google Книгах
Ngram, также называемый N-граммой, представляет собой статистический анализ текста или речевого содержимого, чтобы найти n (число) какого-либо элемента в тексте.
Элемент поиска может быть любым, включая фонемы, префиксы, фразы и буквы. Хотя Ngram неясен за пределами исследовательского сообщества, он используется во многих областях и имеет много последствий для разработчиков, которые кодируют компьютерные программы, которые понимают естественный разговорный язык и реагируют на него .
В случае средства просмотра Google Книг Ngram анализируемый текст взят из огромного количества книг в открытом доступе, которые Google отсканировал, чтобы заполнить свою поисковую систему Google Книги . Для программы просмотра Google Книг Ngram Google относится к тексту, который вы собираетесь искать, как к корпусу . Ngram Viewer агрегирует по языкам, хотя вы можете отдельно анализировать британский и американский английский или объединять их вместе.
Как работает Ngram Viewer
Перейдите в средство просмотра Google Книг на Ngram по адресу books.google.com/ngrams .
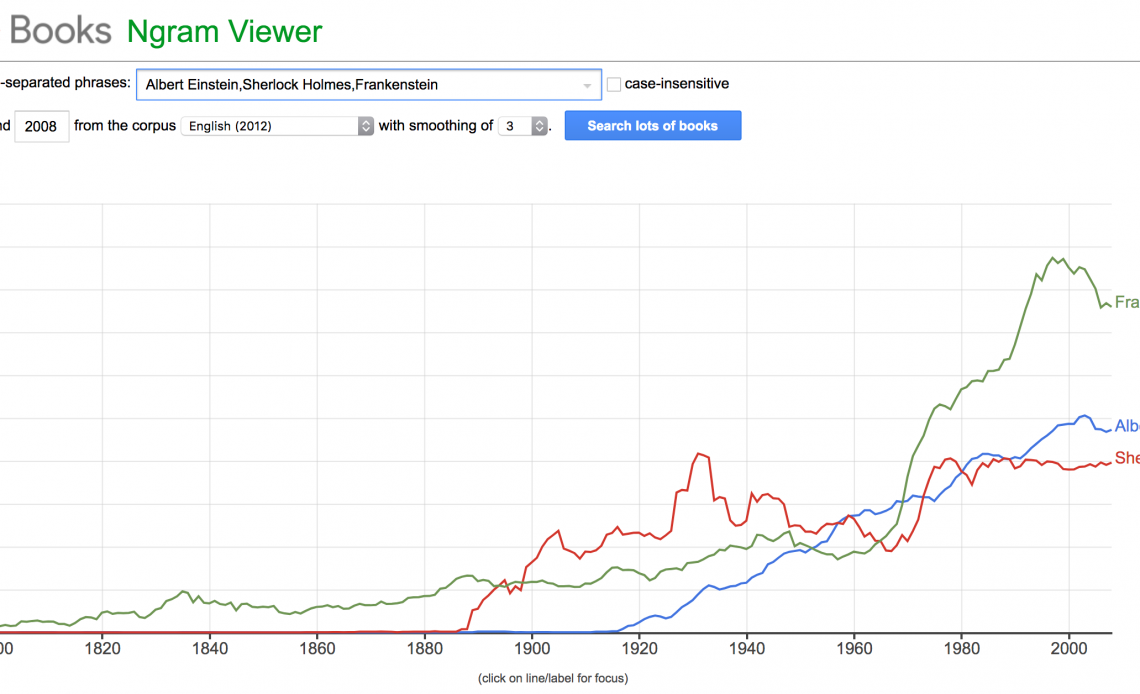
Введите любую фразу или фразы, которые вы хотите проанализировать. Разделяйте каждую фразу запятой. Google предлагает «Альберт Эйнштейн, Шерлок Холмс, Франкенштейн», чтобы вы начали.
В поисках NGram Viewer элементы чувствительны к регистру, в отличие от поисковых запросов Google.
Выберите диапазон дат. По умолчанию от 1800 до 2000.



Выберите корпус. Вы можете искать тексты на иностранных языках или тексты на английском языке, и в дополнение к стандартным вариантам вы можете заметить такие записи, как «Английский (2009)» или «Американский английский (2009)» внизу списка. Это старые версии, которые Google обновил с тех пор, но у вас может быть причина для сравнения со старыми наборами данных. Большинство пользователей могут игнорировать их и сосредоточиться на самых последних корпусах.
Установите уровень сглаживания. Сглаживание относится к тому, насколько гладким является график в конце. Наиболее точное представление отражает уровень сглаживания 0, но этот параметр может быть трудным для чтения. По умолчанию установлено значение 3. В большинстве случаев вам не нужно настраивать его.
Нажмите Поиск много книг .
Используя Google Ngram Viewer, вы можете углубиться в данные. Если вы хотите искать глагол fish вместо существительного fish , вы можете сделать это с помощью тегов. В этом случае вы будете искать fish_VERB.
Google предоставляет полный список команд и другой расширенной документации для использования с Ngram Viewer на своем веб-сайте.
Что показывает Ngram?
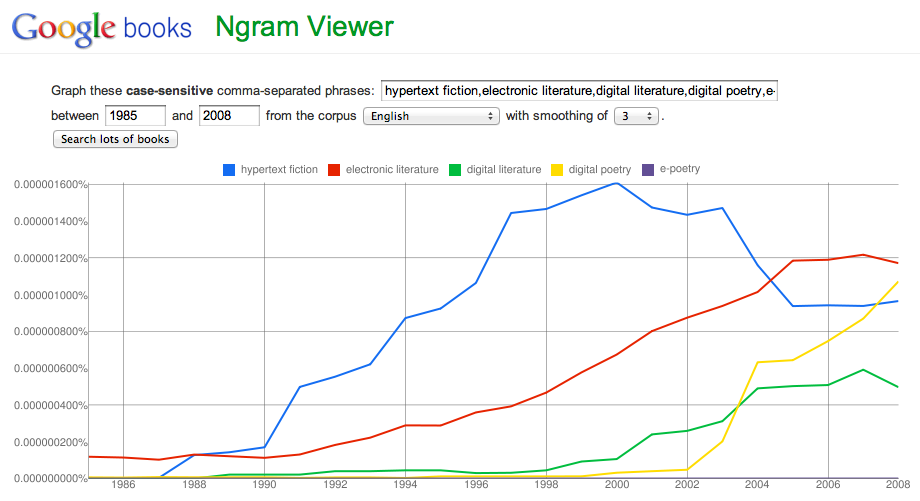
Google Книги Ngram Viewer выводит график, который представляет использование определенной фразы в книгах во времени. Если вы ввели более одного слова или фразы, каждое из них представлено цветной линией, чтобы контрастировать с другими поисковыми терминами. Это похоже на Google Trends , только поиск охватывает более длительный период.
Тематическое исследование
Рассмотрим пример с уксусными пирогами. Они упоминаются в Домике Лоры Ингаллс Уайлдер в сериале « Прерия ». Изучение с помощью веб-поиска Google, чтобы узнать больше о пирогах с уксусом, показывает, что они считаются частью американской южной кухни и действительно сделаны с уксусом
Они обращают внимание на времена, когда не у всех был доступ к свежим продуктам в любое время года, но так ли это на самом деле?
Поищите в Google Ngram Viewer уксусный пирог, и вы увидите некоторые упоминания о пироге как в начале, так и в конце 1800-х годов, много упоминаний в 1940-х годах и растущее число упоминаний в последнее время. Однако с уровнем сглаживания 3 вы видите плато над упоминаниями 1800-х годов. Поскольку за это время было опубликовано не так много книг, а поскольку данные настроены на сглаживание, изображение искажается. Вероятно, только одна книга упоминала пирог с уксусом, и он был усреднен, чтобы избежать всплеска. Установив сглаживание на 0, вы можете видеть, что это именно тот случай. Пик центрируется в 1869 году, и есть еще один пик в 1897 и 1900 годах.
Маловероятно, что в остальное время никто не говорил о пирогах с уксусом: вероятно, были повсюду рецепты, но люди не писали о них в книгах, и это является важным ограничением поисков Ngram.
References
-
«Quantitative analysis of culture using millions of digitized books»
JB Michel et al, Science 2011, DOI: 10.1126/science.1199644 -
↑
«Google Ngram Database Tracks Popularity Of 500 Billion Words»
Huffington Post, 17 December 2010, webpage:
HP8150. -
↑
«Google’s Ngram Viewer: A time machine for wordplay»,
Cnet.com, 17 December 2010, webpage:
CN93. - @searchliaison. «The Google Books Ngram Viewer has now been updated with fresh data through 2019» (in en). .
-
↑ «Google Books Ngram Viewer — University at Buffalo Libraries»,
Lib.Buffalo.edu, 22 August 2011, webpage:
Buf497 - ↑ «Google Books Ngram Viewer info page». https://books.google.com/ngrams/info.
-
«Google Ngram Viewer — Google Books»,
Books.Google.com, May 2012, webpage:
G-Ngrams. -
↑
«Google Ngram Viewer — Google Books» (Information),
Books.Google.com, December 16, 2010, webpage:
G-Ngrams-info:
notes bigrams and use of quotes for words with apostrophes. - Greenfield, Patricia M. (September 2013). «The Changing Psychology of Culture From 1800 Through 2000» (in en). Psychological Science 24 (9): 1722–1731. doi:10.1177/0956797613479387. ISSN 0956-7976. PMID . http://journals.sagepub.com/doi/10.1177/0956797613479387.
- Younes, Nadja; Reips, Ulf-Dietrich (October 2018). «The changing psychology of culture in German-speaking countries: A Google Ngram study: THE CHANGING PSYCHOLOGY OF CULTURE» (in en). International Journal of Psychology 53: 53–62. doi:10.1002/ijop.12428. PMID . https://onlinelibrary.wiley.com/doi/10.1002/ijop.12428.
- The RSA (4 February 2010). «Steven Pinker – The Stuff of Thought: Language as a window into human nature». https://www.youtube.com/watch?v=5S1d3cNge24&t=56m58s.
-
Google Ngrams: OCR and Metadata .
ResourceShelf, 19 December 2010 - Nunberg, Geoff (16 December 2010). «Humanities research with the Google Books corpus». http://languagelog.ldc.upenn.edu/nll/?p=2847.
- Pechenick, Eitan Adam; Danforth, Christopher M.; Dodds, Peter Sheridan; Barrat, Alain (7 October 2015). «Characterizing the Google Books Corpus: Strong Limits to Inferences of Socio-Cultural and Linguistic Evolution». PLOS ONE 10 (10): e0137041. doi:10.1371/journal.pone.0137041. PMID . Bibcode: 2015PLoSO..1037041P.
- Zhang, Sarah. «The Pitfalls of Using Google Ngram to Study Language» (in en-US). WIRED. https://www.wired.com/2015/10/pitfalls-of-studying-language-with-google-ngram/. Retrieved 2017-05-24.
- Koplenig, Alexander (2015-09-02). «The impact of lacking metadata for the measurement of cultural and linguistic change using the Google Ngram data sets—Reconstructing the composition of the German corpus in times of WWII». Digital Scholarship in the Humanities 32 (1): 169–188. 2017-04-01. doi:10.1093/llc/fqv037. ISSN 2055-7671. https://academic.oup.com/dsh/article-abstract/32/1/169/2957375/The-impact-of-lacking-metadata-for-the-measurement.
- Younes, Nadja; Reips, Ulf-Dietrich (2019-03-22). «Guideline for improving the reliability of Google Ngram studies: Evidence from religious terms» (in en). PLOS ONE 14 (3): e0213554. doi:10.1371/journal.pone.0213554. ISSN 1932-6203. PMID . Bibcode: 2019PLoSO..1413554Y.
- Google n-grams and pre-modern Chinese. digitalsinology.org.
- When n-grams go bad. digitalsinology.org.
Cite error: tag with name «SThom» defined in is not used in prior text.
Корпуса
В корпус используемые для поиска, состоят из файлов total_counts, 1-граммов, 2-граммов, 3-граммов, 4 граммов и 5 граммов для каждого языка. Формат файла каждого из файлов: данные, разделенные табуляцией. Каждая строка имеет следующий формат:
- total_counts файл
- год TAB match_count TAB page_count TAB volume_count NEWLINE
- Файл ngram версии 1 (создан в июле 2009 г.)
- ngram TAB год TAB match_count TAB page_count TAB volume_count NEWLINE
- Файл ngram версии 2 (создан в июле 2012 г.)
- ngram TAB год TAB match_count TAB volume_count NEWLINE
Средство просмотра Google Ngram использует match_count для построения графика.
Например, слово «Википедия» из файла версии 2 с английскими 1-граммами хранится следующим образом:
| ngram | год | match_count | volume_count |
|---|---|---|---|
| Википедия | 1904 | 1 | 1 |
| Википедия | 1912 | 11 | 1 |
| Википедия | 1924 | 1 | 1 |
| Википедия | 1925 | 11 | 1 |
| Википедия | 1929 | 11 | 1 |
| Википедия | 1943 | 11 | 1 |
| Википедия | 1946 | 11 | 1 |
| Википедия | 1947 | 11 | 1 |
| Википедия | 1949 | 11 | 1 |
| Википедия | 1951 | 11 | 1 |
| Википедия | 1953 | 22 | 2 |
| Википедия | 1955 | 11 | 1 |
| Википедия | 1958 | 1 | 1 |
| Википедия | 1961 | 22 | 2 |
| Википедия | 1964 | 22 | 2 |
| Википедия | 1965 | 11 | 1 |
| Википедия | 1966 | 15 | 2 |
| Википедия | 1969 | 33 | 3 |
| Википедия | 1970 | 129 | 4 |
| Википедия | 1971 | 44 | 4 |
| Википедия | 1972 | 22 | 2 |
| Википедия | 1973 | 1 | 1 |
| Википедия | 1974 | 2 | 1 |
| Википедия | 1975 | 33 | 3 |
| Википедия | 1976 | 11 | 1 |
| Википедия | 1977 | 13 | 3 |
| Википедия | 1978 | 11 | 1 |
| Википедия | 1979 | 112 | 12 |
| Википедия | 1980 | 13 | 4 |
| Википедия | 1982 | 11 | 1 |
| Википедия | 1983 | 3 | 2 |
| Википедия | 1984 | 48 | 3 |
| Википедия | 1985 | 37 | 3 |
| Википедия | 1986 | 6 | 4 |
| Википедия | 1987 | 13 | 2 |
| Википедия | 1988 | 14 | 3 |
| Википедия | 1990 | 12 | 2 |
| Википедия | 1991 | 8 | 5 |
| Википедия | 1992 | 1 | 1 |
| Википедия | 1993 | 1 | 1 |
| Википедия | 1994 | 23 | 3 |
| Википедия | 1995 | 4 | 1 |
| Википедия | 1996 | 23 | 3 |
| Википедия | 1997 | 6 | 1 |
| Википедия | 1998 | 32 | 10 |
| Википедия | 1999 | 39 | 11 |
| Википедия | 2000 | 43 | 12 |
| Википедия | 2001 | 59 | 14 |
| Википедия | 2002 | 105 | 19 |
| Википедия | 2003 | 149 | 53 |
| Википедия | 2004 | 803 | 285 |
| Википедия | 2005 | 2964 | 911 |
| Википедия | 2006 | 9818 | 2655 |
| Википедия | 2007 | 20017 | 5400 |
| Википедия | 2008 | 33722 | 6825 |
График, построенный программой просмотра Google Ngram Viewer с использованием приведенных выше данных, находится здесь:
Примеры использования NGramsCounter
counter = NGramsCounter(3) # будет 1,2,3 - грамм
counter.add('мама мыла раму') # подсчитываем n-граммы букв
print("размер словаря:", len(counter.root)) # 7
print("слова словаря:", counter.branches()) #
print(counter.ngrams) # число n-грамм n=1,2,3
print(counter.unique() ) # уникальных n-грамм
N1, N2, _ = counter.counts('м') # N1 раз была 'м', N2 - длина текста
print("N('м'), N = ", N1, N2) # 4, 14
print("P('м') = ", counter.prob('м')) # 0.2857 = 4/14 = N1/N2
N1, N2, _ = counter.counts('ма') # N1 раз было 'ма', N2 - было 'м'
print("N('ма'),N('м') = ", N1, N2) # 2, 4
print("P('м=>а') = ", counter.prob('ма')) # 0.5 = 2/4 = N1/N2
print("P(ма=>м) = ", counter.prob('мам')) # 0.5 = 2/4 условная
print("P(мам) = ", counter.prob('мам', False))# 0.083 = 1/12 совместная
print(counter.branches('ма')) # что после ма
counter.all_branches()
# , 1), (, 1),... все ветки
Вероятности в класса NGramsCounter вычисляются как простое отношение N1/N2.
Для более продвинутых способов следует использовать наследников от класса Markov.
counteraddcounter
lm = MarkovLaplas(beta=1, order=3, counter=counter)
print(lm.counter.prob("ру")) # 0
print(lm.prob("ру")) # 0.125 = (0+1)/(1+7)
print(lm.perplexity("мама умыла раму")) # 4.886
- Markov
- MarkovLaplas
- MarkovInterpolated
- MarkovLaplasInterpolated
- MarkovBackoff
n -граммы для приблизительного соответствия
n -граммы также могут использоваться для эффективного приблизительного сопоставления. Преобразуя последовательность элементов в набор n -грамм, она может быть встроена в векторное пространство , что позволяет эффективно сравнивать последовательность с другими последовательностями. Например, если мы преобразуем строки, состоящие только из букв английского алфавита, в односимвольные 3-граммы, мы получим263{\ displaystyle 26 ^ {3}}-мерное пространство (первое измерение измеряет количество вхождений «ааа», второе «ааб» и так далее для всех возможных комбинаций трех букв). Используя это представление, мы теряем информацию о строке. Например, обе строки «abc» и «bca» приводят к одному и тому же 2-граммовому «bc» (хотя {«ab», «bc»} явно не то же самое, что {«bc», «ca» }). Однако мы эмпирически знаем, что если две строки реального текста имеют одинаковое векторное представление (измеренное косинусным расстоянием ), то они, вероятно, будут похожи. Другие показатели также применялись к векторам n -грамм с разными, иногда лучшими результатами. Например,z-значения использовались для сравнения документов путем проверки количества стандартных отклонений в каждом из них.n -грамма отличается от ее среднего появления в большой коллекции или текстовом корпусе документов (которые образуют «фоновый» вектор). В случае небольшого количества результатов оценка g (также известная как g-тест ) может дать лучшие результаты для сравнения альтернативных моделей.
Также можно использовать более принципиальный подход к статистике n -грамм, моделируя сходство как вероятность того, что две строки пришли из одного и того же источника напрямую с точки зрения проблемы байесовского вывода .
Поиск по n- диаграммам также может использоваться для обнаружения плагиата .
Терминология
Биграмма это сочетание из двух букв алфавита. Триграмма из трёх. Из комбинаторики становится понятно, что количество всевозможных биграмм русского языка равно 1089 (33^2). Тогда как для триграмм это число равно 35937 (33^3). Однако, эти числа не совсем справедливы, например биграммы, состоящей из двух мягких знаков быть не может. Даже если считать биграмму как любые два символа в слепленном тексте без пробелов, то всё равно мы никогда не встретим два идущих подряд мягких знака, аналогично с твёрдыми знаками. Поэтому числа преведённые выше являются скорее верхними границами, чем реальными значениями.
Второй вопрос сразу приходящий на ум — почему мы ограничились цифрой три. Можно было пойти дальше и взять четверо-граммы, пяти-граммы и т.д. Можно было, но это не принесло бы нам пользы. К сожалению, сейчас я не могу сослаться на какую-либо работу, но могу сказать, что н-граммы после трёх уже не так эффективны, а число их слишком велико. Для простого анализа текста обычно хватает триграмм.
Библиотеки для NLP
NLTK (Natural Language ToolKit)
Пакет библиотек и программ для символьной и статистической обработки естественного языка, написанных на Python и разработанных по методологии SCRUM. Содержит графические представления и примеры данных. Поддерживает работу с множеством языков, в том числе, русским.
Плюсы:
- Наиболее известная и многофункциональная библиотека для NLP;
- Большое количество сторонних расширений;
- Быстрая токенизация предложений;
- Поддерживается множество языков.
Минусы
- Медленная;
- Сложная в изучении и использовании;
- Работает со строками;
- Не использует нейронные сети;
- Нет встроенных векторов слов.
spaCy
Библиотека, разработанная по методологии SCRUM на языке Cypthon, позиционируется как самая быстрая NLP библиотека. Имеет множество возможностей, в том числе, разбор зависимостей на основе меток, распознавание именованных сущностей, пометка частей речи, векторы расстановки слов. Не поддерживает русский язык.
Плюсы:
- Самая быстрая библиотека для NLP;
- Простая в изучении и использовании;
- Работает с объектами, а не строками;
- Есть встроенные вектора слов;
- Использует нейронные сети для тренировки моделей.
Минусы
- Менее гибкая по сравнению с NLTK;
- Токенизация предложений медленнее, чем в NLTK;
- Поддерживает маленькое количество языков.
scikit-learn
Библиотека scikit-learn разработана по методологии SCRUM и предоставляет реализацию целого ряда алгоритмов для обучения с учителем и обучения без учителя через интерфейс для Python. Построена поверх SciPy. Ориентирована в первую очередь на моделирование данных, имеет достаточно функций, чтобы использоваться для NLP в связке с другими библиотеками.
Плюсы:
- Большое количество алгоритмов для построения моделей;
- Содержит функции для работы с Bag-of-Words моделью;
- Хорошая документация.
Минусы
- Плохой препроцессинг, что вынуждает использовать ее в связке с другой библиотекой (например, NLTK);
- Не использует нейронные сети для препроцессинга текста.
gensim
Python библиотека, разработанная по методологии SCRUM, для моделирования, тематического моделирования документов и извлечения подобия для больших корпусов. В gensim реализованы популярные NLP алгоритмы, например, word2vec. Большинство реализаций могут использовать несколько ядер.
Плюсы:
- Работает с большими датасетами;
- Поддерживает глубокое обучение;
- word2vec, tf-idf vectorization, document2vec.
Минусы
- Заточена под модели без учителя;
- Не содержит достаточного функционала, необходимого для NLP, что вынуждает использовать ее вместе с другими библиотеками.
Балто-славянские языки имеют сложную морфологию, что может ухудшить качество обработки текста, а также ограничить использование ряда библиотек. Для работы со специфичной русской морфологией можно использовать, например, морфологический анализатор pymorphy2 и библиотеку для поиска и извлечения именованных сущностей Natasha
Сглаживание, откат и интерполяция
Проблему нулевых условных вероятностей можно решать различными способами.
Самый простой и грубый — это сделать нулевые вероятности маленькими, но ненулевыми.
Для этого используют сглаживание Lidstone,
частный случай которого ($\gamma=1$) называется сглаживанием Лапласа
$$
\tilde{P}(w_1,…,w_{n-1}\Rightarrow w_n) = \frac{ N(w_1…w_n) + \gamma}{N(w_1…w_{n-1})+|\mathcal{V}|\cdot\gamma},
$$
где $N(…)$ — число появления последовательностей слов в тексте, а $+|\mathcal{V}|$ — число слов в словаре.
Несложно видеть, что сумма $\tilde{P}$ по всем $w_n\in \mathcal{V}$ равна единице.
Заметим, что, если в обучающем корпусе нет n-граммы
$(w_1…w_{n-1})$, то вероятности всех слов словаря будет равна $1/|\mathcal{V}|$.

Другой способ — это откат (backoff). Так,
если, например, $P(w_1,w_2 \Rightarrow w_3)$ равна нулю (3-грамма $w_1w_2w_3$ не встретилась в обучающем корпусе),
то берут вероятность $P(w_2 \Rightarrow w_3)$. Если и она равна нулю, то просто $P(w_3)$.
Такой метод требует дополнительной нормировки,
т.к. сумма получающихся вероятностей по всем словам словаря, вообще говоря, не равна 1.
Соответственно, перплексия будет вычислена неверно. Существуют различные вариации
backoff-стратегии устраняющие эту проблему.
Достаточно простой способ борьбы с нулевыми вероятностями — это интерполяция,
при помощи которой условную вероятность вычисляют следущим образом:
$$
\tilde{P}(w_1…w_{n-1}\Rightarrow w_n) =
\frac{ P(w_1…w_n\Rightarrow w)
+\lambda_1\, P(w_2…w_{n-1}\Rightarrow w)
+…
+ \lambda_n\,P(w)
}
{
1+\lambda_1+…+\lambda_n
}.
$$
Коэффициенты $\lambda_1,…\lambda_n$ должны убывать (больший вес дают более «длинные» условные вероятности).
Однако, если они равны нулю, информация о вероятности символа $w_n$ будет получена из более короткой
условной вероятности и $\tilde{P}$ никогда не будет нулевой.
Например, можно выбрать $\lambda_k=\beta^k$, где $\beta \in $ — параметр модели.
Формально, сумма этого выражения по всем $w$ из словаря равна единице
(благодаря знаменателю). Однако, это будет так, только, если $P(w_{n-k}…w_{n-1} \Rightarrow w_n)$
отлично от нуля хотя бы для одного $w_n$.
Поэтому, и в числителе, и в знаменателе следует убирать первые слагаемые для
$P(w_{1}…w_{k} \Rightarrow w)$ у которых $N(w_{1}…w_{k})=0$ (т.е. $P=0$ для всех слов словаря).
Можно также ликвидировать слагаемые с малым значение $N(w_{1}…w_{k})$ (т.к. они дают ненадёжное значение
вероятности) или учитывать в весах
вероятности.
Критика
Набор данных подвергся критике за то, что он полагался на неточные OCR, переизбыток научной литературы и большое количество неправильно датированных и категоризированных текстов. Из-за этих ошибок и из-за неконтролируемой предвзятости (например, увеличение количества научной литературы, что вызывает снижение популярности других терминов), рискованно использовать этот корпус для изучения языка или проверки теорий. Поскольку набор данных не включает метаданные, он может не отражать общие языковые или культурные изменения и могу только намекнуть на такой эффект.
Были предложены рекомендации по проведению исследований с данными из Google Ngram, которые решают многие из проблем, рассмотренных выше.
Проблемы с OCR
Оптическое распознавание символов, или OCR, не всегда надежно, и некоторые символы могут быть неправильно отсканированы. В частности, системные ошибки, такие как путаница «s» и «f» в текстах до XIX века (из-за использования длинные s который был похож по внешнему виду на «f») может вызвать системную ошибку. Хотя Google Ngram Viewer утверждает, что результаты являются надежными начиная с 1800 года, плохое распознавание текста и недостаточность данных означают, что частоты, указанные для таких языков, как китайский, могут быть точными только с 1970 года, при этом более ранние части корпуса не показывают результатов для общих терминов. , и данные за несколько лет, содержащие более 50% шума.
Эксплуатация и ограничения
Запятые ограничивают введенные пользователем условия поиска, указывая на каждое отдельное слово или фразу, которые необходимо найти. Средство просмотра Ngram возвращает построенную линейную диаграмму в течение нескольких секунд после того, как пользователь нажмет клавишу Enter или кнопку «Поиск» на экране.
В качестве поправки на большее количество книг, опубликованных в течение некоторых лет, данные нормализуются как относительный уровень по количеству книг, издаваемых в каждом году.
Из-за ограничений размера базы данных Ngram в базе данных индексируются только совпадения, найденные не менее чем в 40 книгах; в противном случае база данных не смогла бы сохранить все возможные комбинации.
Как правило, условия поиска не могут заканчиваться знаками препинания, хотя можно искать отдельную точку (точку). Кроме того, завершающий вопросительный знак (например, «Почему?») вызовет повторный поиск вопросительного знака отдельно.
Отсутствие точек в аббревиатурах позволит использовать форму сопоставления, например, использовать «RMS» для поиска «RMS» по сравнению с «RMS».