
РейсРадар24
Как видно из названия, лучшая функция в FlightRadar24 Карта, на которой показаны самолеты, путешествующие по миру. Вы можете выбрать рейс, чтобы увидеть дополнительную информацию, такую как маршрут, расчетное время прибытия, скорость, высоту и многое другое. Также легко найти отдельный рейс по номеру рейса, аэропорту или авиакомпании. При выборе конкретного аэропорта отобразится дополнительная информация, например Текущие погодные условия и статистика задержек.
Если вам когда-нибудь было интересно, какие рейсы выполняются в настоящее время, просто наведите свое устройство на небо, чтобы увидеть информацию о рейсе и изображение реального самолета. Вы даже можете точно увидеть, что пилот самолета в данный момент просматривает в 3D. Это отличное применение в реальном мире для технологии дополненной реальности.
Варианты подписки предоставляют дополнительные функции, такие как дополнительная история поездок и многое другое.
Скачать: FlightRadar24 для ОС iOS | Android (Бесплатно, доступна подписка)
Текст сопротивляется
Тексты, для которых нужно определить язык, в основном милые и пушистые большие и грамотно написанные. Определители языков такие любят. И все же некоторые из них содержат детали, затрудняющие точное определение языков:
- вставки слов/словосочетаний неосновного языка (термины, имена собственные, обозначения и так далее) встречаются довольно часто и порой “подгребаются” под основной язык;
- наличие в тексте нескольких языков с часто чередующимися короткими фрагментами;
- большое количество формул, аббревиатур, схем…;
- омоглифы — вишенка на торте, большое количество омоглифов не оставляет шансов автоматическому определителю языков понять, на каком же языке текст.
Результат определения языков текста CLD2 в зависимости от количества омоглифов в тексте
По вертикали отложена доля текста, по горизонтали – отношение количества омоглифов к количеству слов в тексте. Если в тексте присутствует один замененный символ на два слова, доля текста, на которой язык определился верно, начинает резко падать. При трех омоглифах на два слова почти на всем тексте язык не определен. Правда, есть и хорошая новость: для русского, английского и казахского языков случаи неверного определения языка крайне редки.
Для решения этой и других проблем, с которыми не справляется CLD2, мы разработали эвристический алгоритм. Это алгоритм использует многократный запуск CLD2, определение языка слов с помощью словарей и статистические методы.
Yargy-парсер — извлечение структурированное информации из текстов на русском языке с помощью грамматик и словарей
Yargy-парсерТомита-парсераконтекстно-свободных грамматикстатью про Yargy и библиотеку Natasha
вводный разделсправочникCookbookt.me/natural_language_processing
- ;
- ;
- .
- ;
- ;
- .
- ;
- (особенно полезно, ни одно решение на практике без этого приёма не обходится).
репозиторий с примерами
- парсинг объявлений с Авито;
- разбор рецептов из ВК.
natasha-usage
- разбор фида о работе метро в Спб;
- парсинг объявлений о сдаче жилья в соцсетях;
- извлечение атрибутов из названий авто покрышек;
- парсинг вакансий из канала jobs чата ODS;
natasha.github.io
Хараппский язык
Хараппанцы из долины Инда на границе Пакистана и Индии — это, вероятно, самая великая древняя цивилизация, о которой вы никогда не слышали. С 3300 года до н.э. эти строители, администраторы и любители лазурита строили свои сложные города, занимались горной добычей, торговали тем, что находили, и общались друг с другом на языке, который отличается от всех остальных.
Многое из того, что сохранилось от хараппского языка, говорит об их практическом применении. Пиктограммы обычно встречаются на печатях, которые, скорее всего, использовались для маркировки товаров или других предметов, и поэтому были техническим решением, а не творческим инструментом.
Тоже интересно: Кто на самом деле построил пирамиды Гизы? Загадочные изумрудные скрижали Тота могут дать ответ
Но это делает расшифровку текста весьма проблематичной, поскольку почти вся хараппская письменность сохранилась в виде очень коротких инвентарных фрагментов текста. Относительно недавно в попытках понять хараппский текст был достигнут значительный прогресс, и есть надежда, что когда-нибудь мы сможем узнать больше о древней культуре.
Шаг 6: синтаксический анализ на основе грамматики зависимостей
Теперь необходимо выяснить, как связаны друг с другом слова в предложении. Для этого проводят синтаксический анализ на основе грамматики (или дерева) зависимостей.
Цель — построить дерево, в котором к каждому слову соответствует одно непроизводное слово. Корень дерева — это ключевой глагол предложения. Вот так будет выглядеть дерево синтаксического анализа вначале:

Но можно пойти дальше: помимо подбора непроизводных слов, можно вычислить тип взаимосвязи между двумя словами в предложении:
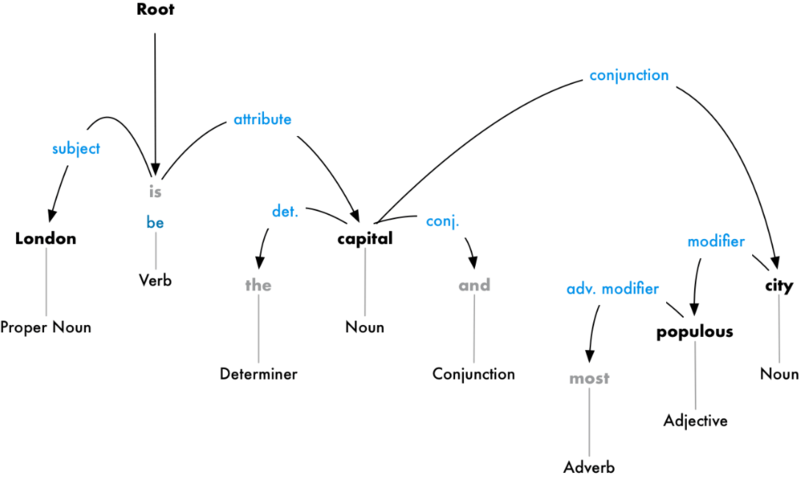
Из этого дерева видно, что подлежащим в предложении является слово «London», которое связано со словом «capital» через слово «be». Удалось выделить значимую информацию: Лондон — это столица. Продолжив анализ, можно выяснить, что Лондон является столицей Соединённого Королевства.
Аналогично тому, как выше модель МО угадывала, к какой части речи относятся слова, для парсинга зависимостей в модель вводят слова и получают некий результат на выходе. Анализ связей между словами — весьма трудоёмкая задача, подробного описания которой хватит на целую отдельную статью. Начать можно со статьи «Parsing English in 500 Lines of Python» Мэтью Хоннибала.
Хотя в 2015 году этот подход считался общепринятым, на сегодняшний день он уже устарел и больше не используется даже самим автором. В 2016 году Google выпустила новый анализатор зависимостей Parsey McParseface, превосходящий остальные инструменты благодаря новому подходу на основе глубокого обучения, который быстро набрал популярность в отрасли. Годом позже компания даже выпустила новую, ещё более совершенную модель ParseySaurus. Таким образом, технологии синтаксического анализа не стоят на месте и постоянно улучшаются.
Важно отметить, что многие предложения на английском языке могут толковаться двояко и нелегко поддаются анализу. В таких случаях модель просто делает предположение, исходя из того, какой вариант ей кажется более вероятным
Но этот способ имеет свои недостатки, так как иногда ответы моделей достаточно далеки от истины. На сайте spaCy можно запустить синтаксический анализ на основе дерева зависимостей для любого предложения.
Языковая сложность и сложность для изучения
Как пишет Даль, зрелые языковые паттерны часто оказываются самыми сложными для выучивания — если речь идет о выучивании взрослым человеком. На финальном этапе созревания возрастает число нерегулярных явлений, для которых лингвисту нужно заводить отдельные правила — а тому, кто учит язык, приходится запоминать гораздо больше закономерностей. Пример такой сложной системы — русское именное словоизменение, то есть то, как разные имена изменяются по падежам и числам. К сожалению, оно не вполне работает по схеме «основа слова + показатель падежа». В основах могут возникать различные чередования, к тому же нетривиальна постановка ударения. Чтобы как-то описать эту сложную систему, русскому лингвисту А. А. Зализняку пришлось написать целую книгу.
Письменность Ронго-Ронго
В 1864 году испанец Эжен Эйро сообщил об обнаружении странной пиктографической письменности на острове Рапа-Нуи, также известном как остров Пасхи. Знаки, запечатленные на кусках дерева, называлась «Ронго-Ронго», что на языке местных жителей означает «напевать».
К этому моменту Рапа-Нуи уже был похож на себя сегодняшнего, колонизированного испанцами в 1770 году и опустошенного европейскими болезнями. К 1860-м годам на острове оставалось всего около 3000 человек, и половина из них была похищена перуанскими рабовладельцами в 1862 году.
Тоже интересно: Землей 240 тысяч лет правили 8 царей, пришедших с небес
Такая резкая убыль коренного населения привела к тому, что многое на острове было утеряно, и не в последнюю очередь его история. Поскольку никто не помнит, как читать древние письмена, и сохранилось слишком мало примеров, чтобы попытаться восстановить их, скорее всего, традиционная история Рапа-Нуи потеряна навсегда.
Оценка качества
Оценивать качество работы алгоритмов будем на данных из соц.сетей за случайное время, взятых из системы YouScan (приблизительно 500 тысяч упоминаний), поэтому в выборке будет больше русского и английского языков, 43% и 32% соответственно, украинского, испанского и португальского – около 2% каждого, из остальных языков меньше 1%. За правильный таргет мы будем брать разметку через google translate, так как на данный момент гугл очень хорошо справляется не только с переводом, а и с определением языка текстов. Конечно, его разметка неидеальна, но в большинстве случаев ей можно доверять.
Метриками для оценки качества определения языка будут точность, полнота и f1. Давайте их посчитаем и выведем в таблице:
| model | cld2 | ft | ans | ||||||
|---|---|---|---|---|---|---|---|---|---|
| metrics | prec | rec | f1 | prec | rec | f1 | prec | rec | f1 |
| ar | 0.992 | 0.725 | 0.838 | 0.918 | 0.697 | 0.793 | 0.968 | 0.788 | 0.869 |
| az | 0.95 | 0.752 | 0.839 | 0.888 | 0.547 | 0.677 | 0.914 | 0.787 | 0.845 |
| bg | 0.529 | 0.136 | 0.217 | 0.286 | 0.178 | 0.219 | 0.408 | 0.214 | 0.281 |
| en | 0.949 | 0.844 | 0.894 | 0.885 | 0.869 | 0.877 | 0.912 | 0.925 | 0.918 |
| es | 0.987 | 0.653 | 0.786 | 0.709 | 0.814 | 0.758 | 0.828 | 0.834 | 0.831 |
| fr | 0.991 | 0.713 | 0.829 | 0.53 | 0.803 | 0.638 | 0.713 | 0.81 | 0.758 |
| id | 0.763 | 0.543 | 0.634 | 0.481 | 0.404 | 0.439 | 0.659 | 0.603 | 0.63 |
| it | 0.975 | 0.466 | 0.631 | 0.519 | 0.778 | 0.622 | 0.666 | 0.752 | 0.706 |
| ja | 0.994 | 0.899 | 0.944 | 0.602 | 0.842 | 0.702 | 0.847 | 0.905 | 0.875 |
| ka | 0.962 | 0.995 | 0.979 | 0.959 | 0.905 | 0.931 | 0.958 | 0.995 | 0.976 |
| kk | 0.908 | 0.653 | 0.759 | 0.804 | 0.584 | 0.677 | 0.831 | 0.713 | 0.767 |
| ko | 0.984 | 0.886 | 0.933 | 0.94 | 0.704 | 0.805 | 0.966 | 0.91 | 0.937 |
| ms | 0.801 | 0.578 | 0.672 | 0.369 | 0.101 | 0.159 | 0.73 | 0.586 | 0.65 |
| pt | 0.968 | 0.753 | 0.847 | 0.805 | 0.771 | 0.788 | 0.867 | 0.864 | 0.865 |
| ru | 0.987 | 0.809 | 0.889 | 0.936 | 0.933 | 0.935 | 0.953 | 0.948 | 0.95 |
| sr | 0.093 | 0.114 | 0.103 | 0.174 | 0.103 | 0.13 | 0.106 | 0.16 | 0.128 |
| th | 0.989 | 0.986 | 0.987 | 0.973 | 0.927 | 0.95 | 0.979 | 0.986 | 0.983 |
| tr | 0.961 | 0.639 | 0.768 | 0.607 | 0.73 | 0.663 | 0.769 | 0.764 | 0.767 |
| uk | 0.949 | 0.671 | 0.786 | 0.615 | 0.733 | 0.669 | 0.774 | 0.777 | 0.775 |
| uz | 0.666 | 0.512 | 0.579 | 0.77 | 0.169 | 0.278 | 0.655 | 0.541 | 0.592 |
По результатам хорошо видно, что у подхода cld2 очень высокая точность определения языка, только для непопулярных языков она падает ниже 90%, и в 90% случаев результат лучше, чем у fasttext’a. При примерно одинаковой полноте для двух подходов, f1 скор больше у cld2.
Особенность cld2 модели в том, что она выдает прогноз только для тех сообщений, где она достаточно уверена, это объясняет высокую точность. Модель fasttext’a выдает ответ для большинства сообщений, поэтому точность существенно ниже, но странно, что полнота не существенно выше, а в половине случаев – ниже. Но если «подкрутить» порог для модели fasttext’a, то можно улучшить точность.
Переводчик Google
возможно, использовал Google Переводчик Из прошлого. Но знаете ли вы, что у нее есть выбор?Автоматическое распознавание языка«Что позволяет легко определять неизвестные языки?
Чтобы использовать его, скопируйте текст на неизвестном языке и перейдите в Google Translate. Вставьте текст в поле слева. Над этим полем вы должны увидеть опцию Автоматическое распознавание языка. Если вы его не видите, щелкните стрелку раскрывающегося списка, чтобы отобразить все поддерживаемые языки, и выберите Автоматическое распознавание языка.
Через мгновение текст определения языка должен измениться на — Обнаружено. Это позволяет вам легко выбрать язык и посмотреть, что говорится в тексте, для загрузки.
تقدم Google Переводчик Множество замечательных функций на Свои собственные телефонные приложения тоже. Там вы можете перевести почерк Или даже используйте камеру, чтобы перевести текст, который вы видите перед собой.
Python: как определить язык?
TextBlob . Требуется пакет NLTK, использует Google.
pip install textblob
Полиглот . Требуется numpy и некоторые загадочные библиотеки, вряд ли они будут работать в Windows . (Для Windows, получить соответствующие версии PyICU , Morfessor и PyCLD2 от сюда , то просто pip install downloaded_wheel.whl ) . Способен обнаружить тексты со смешанными языками.
pip install polyglot
Чтобы установить зависимости, запустите: sudo apt-get install python-numpy libicu-dev
chardet также имеет функцию определения языков, если есть символьные байты в диапазоне (127-255):
pip install chardet
langdetect Требуется большой объем текста. Под капотом он использует недетерминированный подход. Это означает, что вы получите разные результаты для одного и того же образца текста. Документы говорят, что вам нужно использовать следующий код, чтобы определить его:
pip install langdetect
guess_language Может обнаруживать очень короткие образцы с помощью этого средства проверки правописания со словарями.
pip install guess_language-spirit
langid предоставляет оба модуля
и инструмент командной строки:
pip install langid
FastText — это классификатор текста, может использоваться для распознавания 176 языков с соответствующими моделями классификации языков . Скачайте эту модель , затем:
pip install fasttext
pyCLD3 — это модель нейронной сети для идентификации языка. Этот пакет содержит код вывода и обученную модель.
pip install pycld3
Возникает проблема, langdetect когда он используется для распараллеливания, и он не работает. Но spacy_langdetect это оболочка для этого, и вы можете использовать ее для этой цели. Вы также можете использовать следующий фрагмент:
Если вы ищете библиотеки , которая быстро с длинными текстами , polyglot и fastext делают самую лучшую работу здесь.
Я взял 10 000 документов из коллекции грязных и случайных HTML-кодов, и вот результаты:
Я заметил, что многие методы ориентированы на короткие тексты, вероятно, потому, что это сложная проблема: если у вас много текста, действительно легко определять языки (например, можно просто использовать словарь!). Однако это затрудняет поиск простого и подходящего метода для длинных текстов.

В зависимости от случая вам может быть интересно использовать один из следующих методов:
Метод 0: используйте API или библиотеку
Обычно с этими библиотеками возникает несколько проблем, потому что некоторые из них не подходят для небольших текстов, некоторые языки отсутствуют, они медленные, требуют подключения к Интернету, не бесплатны, . Но в целом они подходят для большинства потребностей .
Метод 1: языковые модели
Языковая модель дает нам вероятность последовательности слов
Это важно, потому что позволяет нам надежно определять язык текста, даже если текст содержит слова на других языках (например: «Hola» означает «привет» на испанском языке » )
Вы можете использовать N языковых моделей (по одной на каждый язык), чтобы оценить свой текст. Обнаруженный язык будет языком модели, которая дала вам наивысшую оценку.
Если вы хотите создать для этого простую языковую модель, я бы выбрал 1-грамм. Для этого вам нужно всего лишь подсчитать, сколько раз появлялось каждое слово из большого текста (например, Корпус Википедии на языке «X»).
Тогда вероятность слова будет равна его частоте, деленной на общее количество проанализированных слов (сумма всех частот).
Если текст для обнаружения довольно большой, я рекомендую выбрать N случайных слов, а затем использовать сумму логарифмов вместо умножения, чтобы избежать проблем с точностью с плавающей запятой.
Метод 2: пересекающиеся множества
Еще более простой подход — подготовить N наборов (по одному на каждый язык) из M самых часто встречающихся слов. Затем пересекайте свой текст с каждым набором. Набор с наибольшим количеством пересечений будет вашим обнаруженным языком.
Метод 3: сжатие почтового индекса
Это скорее любопытство, чем что-либо еще, но вот оно . Вы можете сжать свой текст (например, LZ77), а затем измерить расстояние zip относительно эталонного сжатого текста (целевой язык). Лично мне он не понравился, потому что он медленнее, менее точен и менее информативен, чем другие методы. Тем не менее, у этого метода могут быть интересные приложения. Чтобы узнать больше: языковые деревья и архивирование
Языковая сложность
Интуитивно понятно, что системы могут быть более или менее сложными. В 2019 году компьютеры устроены сложнее, чем в 1999-м. Но как измерить сложность того или иного объекта?
Типолог Эстен Даль использовать понятие колмогоровской сложности: сложность объекта определяется длиной кратчайшего описания этого объекта, или, иначе говоря, кратчайшего алгоритма, который этот объект генерирует. В качестве примера рассмотрим две строки:
Очевидно, что в первой строке трижды повторяется число 185, а во второй — 1857. Мы можем заменить каждую строку более компактным описанием — просто указать, какой объект и сколько раз повторяется:
Но описание второй строки в любом случае длиннее, чем описание первой, потому что повторяющийся объект сам по себе длиннее и его нельзя дополнительно сократить. Это значит, согласно данному выше определению, что вторая строка сложнее первой.
Примерно так же можно измерить сложность отдельных языковых объектов. Чтобы привести самый простой пример, вернемся к падежам. В русском языке, согласно , шесть основных падежей:
(Мы намеренно не рассматриваем особые случаи вроде второго родительного падежа, так как «каждая из этих форм свойственна ограниченному кругу слов и встречается в особых контекстных условиях».)
Индонезийский язык, в отличие от русского, падежей не имеет вообще, у него в целом бедная морфология. Существительные не могут изменяться — достаточно сравнить следующие примеры с их русскими переводами:
Из примеров (1) и (2) видно, что в индонезийском языке нет аналогов винительному или именительному падежу, а из примера (3) — что в нем нет аналога родительному. Во всех трех случаях существительные не изменяются.
С другой стороны, есть языки, в которых гораздо больше падежей, чем в русском. Например, в нахско-дагестанских языках, на которых говорят в Дагестане.
В мегебском языке 8 грамматических падежей и 30 пространственных.
Пространственные падежи выражают положение объектов в пространстве (в русском языке для этого используются предлоги и наречия).
(Для простоты деление на морфемы дается только для существительных в пространственных падежах; «3» значит третий именной класс, что-то в духе русского среднего рода.)

В данном случае мы проделали очень простую процедуру: посчитали падежи и сравнили их количество. Но нужно понимать, что это только один из многих аспектов языковой сложности, даже среди явлений, связанных с падежной системой.
8: Ронгоронго
Загадочные языки острова Пасхи
Остров Пасхи, одно из самых загадочных и отдаленных мест в мире. На протяжении сотен лет он был обителью загадочной культуры, известной созданием больших статуй с каменными лицами. Остров Пасхи был настолько малым, что этой культуре пришлось бороться за выживание прежде чем кануть в Лету. Однако остался загадочный нерасшифрованный язык, известный как Ронгоронго. Для меня Рон Горонго звучит как что-то вроде… имени мультяшного частного детектива. Но это всего лишь мое мнение. Были найдены десятки деревянных табличек со странными символами. Если читать мысли в разных направлениях, возможно, этот язык связан с лунными циклами, но это всего лишь одна из теорий.
Мы не знаем, когда он был придуман, но, по крайней мере, до 1860-х годов язык еще использовался. За десятилетия до исчезновения никто не мог вспомнить, как он читается. Также к тому времени большая часть деревянных табличек использовалась в качестве дров, и у нас осталось их всего несколько десятков. Если Ронгоронго когда-нибудь переведут, возможно, эти таблички раскроют предназначение каменных голов. Но этот день, скорее всего, никогда не наступит.
Что такое обработка естественного языка
Обработка естественного языка (далее NLP — Natural language processing) — область, находящаяся на пересечении computer science, искусственного интеллекта и лингвистики. Цель заключается в обработке и “понимании” естественного языка для перевода текста и ответа на вопросы.
С развитием голосовых интерфейсов и чат-ботов, NLP стала одной из самых важных технологий искусственного интеллекта. Но полное понимание и воспроизведение смысла языка — чрезвычайно сложная задача, так как человеческий язык имеет особенности:
- Человеческий язык — специально сконструированная система передачи смысла сказанного или написанного. Это не просто экзогенный сигнал, а осознанная передача информации. Кроме того, язык кодируется так, что даже маленькие дети могут быстро выучить его.
- Человеческий язык — дискретная, символьная или категориальная сигнальная система, обладающая надежностью.
- Категориальные символы языка кодируются как сигналы для общения по нескольким каналам: звук, жесты, письмо, изображения и так далее. При этом язык способен выражаться любым способом.
Где применяется NLP
Сегодня быстро растет количество полезных приложений в этой области:
- поиск (письменный или устный);
- показ подходящей онлайн рекламы;
- автоматический (или при содействии) перевод;
- анализ настроений для задач маркетинга;
- распознавание речи и чат-боты,
- голосовые помощники (автоматизированная помощь покупателю, заказ товаров и услуг).
Глубокое обучение в NLP
Существенная часть технологий NLP работает благодаря глубокому обучению (deep learning) — области машинного обучения, которая начала набирать обороты только в начале этого десятилетия по следующим причинам:
- Накоплены большие объемы тренировочных данных;
- Разработаны вычислительные мощности: многоядерные CPU и GPU;
- Созданы новые модели и алгоритмы с расширенными возможностями и улучшенной производительностью, c гибким обучением на промежуточных представлениях;
- Появились обучающие методы c использованием контекста, новые методы регуляризации и оптимизации.
Большинство методов машинного обучения хорошо работают из-за разработанных человеком представлений (representations) данных и входных признаков, а также оптимизации весов, чтобы сделать финальное предсказание лучше.
В глубокомобучении алгоритм пытается автоматически извлечь лучшие признаки или представления из сырых входных данных.
Созданные вручную признаки часто слишком специализированные, неполные и требуют время на создание и валидацию. В противоположность этому, выявленные глубоким обучением признаки легко приспосабливаются.
Глубокое обучение предлагает гибкий, универсальный и обучаемый фреймворк для представления мира как в виде визуальной, так и лингвистической информации. Вначале это привело к прорывам в областях распознавания речи и компьютерном зрении. Эти модели часто обучаются с помощью одного распространенного алгоритма и не требуют традиционного построения признаков под конкретную задачу.
Недавно я закончил исчерпывающий курс по NLP с глубоким обучением из Стэнфорда.
Этот курс — подробное введение в передовые исследование по глубокому обучению, примененному к NLP. Курс охватывает представление через вектор слов, window-based нейросети, рекуррентные нейросети, модели долгосрочной-краткосрочной памяти, сверточные нейросети и некоторые недавние модели с использованием компонента памяти. Со стороны программирования, я научился применять, тренировать, отлаживать, визуализировать и создавать собственные нейросетевые модели.
Замечание: доступ к лекциям из курса и домашним заданиям по программированию находится в этом репозитории.
10: Енохианский
Загадочные языки оккультизма
В средние века считалось, что существует божественный язык. Язык, на котором говорят ангелы и сам Бог. Для многих этот язык можно было найти в частных книгах для записей человека по имени Джон Ди. Ди был ведущим оккультистом Англии, много лет изучавшим алхимию и магию. В конце концов он стал советником королевы Елизаветы. Говорили, что он даже мог вызывать демонов и ангелов, которые научили Ди таинственному языку в 1582 году. Сохраненный в его трудах язык не похож ни на один другой. Его алфавит и грамматика уникальны — даже чужеземны.
Читать нужно слева направо, каждая буква имеет английский эквивалент и полный перевод. Молва гласила, что, разговаривая на этом языке, можно было совершать всевозможные небесные подвиги. В последующие века некоторые пришли к выводу, что на самом деле это язык зла. Что ангелы, открывшие его, были скрытыми демонами. Большинство осудило его и окрестило демоническим языком. Но всегда были те, кто верил, что это божественный язык. Мнение современных лингвистов разделилось. Енохианский язык легко мог оказаться вымыслом. Но в нем есть фонетические элементы, которых нет ни в одном другом языке, и сегодня он все еще изучается оккультистами.
1.Rememberry
Первым в этом списке идет Rememberry.Rememberry – это бесплатное расширение для браузера Chrome, которое позволяет переводить любой текст, который вы видите во время просмотра
Возможности программы впечатляют разнообразием, позволяя переводить текст, выделяя его мышью, используя контекстное меню или даже настраивая горячие клавиши. Это позволяет быстро и легко переводить то, что вы читаете
Имеются опции для машинного автоматического произношения, направления и изменения языка, а также множество синонимов и определений. Это работает для более чем 100 различных языков
Однако перевод текста с помощью Rememberry – это только начало. Когда Rememberry действительно помогает вам укрепить ваше понимание языка, это его обучающие функции
Похожие: Альтернативы Duolingo: Лучшие бесплатные приложения для изучения языков
При переводе с помощью Rememberry вы увидите возможность выбрать подходящий перевод слова или фразы, которую вы только что искали. После выбора эти слова и фразы войдут в словарный запас Rememberry
Этот словарь является тем набором, который Rememberry использует для тестирования вас. Вы даже можете разделить его на более мелкие наборы, которые Rememberry называет колодами, если пожелаете
Далее, Rememberry предлагает множество различных режимов обучения, таких как письменный и аудирование. Вы можете настроить эти различные режимы обучения с помощью ряда различных параметров
Если вы забываете об учебе, не беспокойтесь об этом.Rememberry также имеет возможность отправлять вам напоминания, если вы давно не занимались
Доступные публичные решения
Compact Language Detector 2
CLD2 – это вероятностная модель на основе машинного обучения (Наивный Баессовский классификатор), которая может определять 83 различных языка для текста в формате UTF-8 или html/xml. Для смешанных языков модель возвращает топ-3 языка, где вероятность расчитывается как приблизительный процент текста от общего числа байт. Если модель не уверена в своем ответе, то возвращает тег «unc».
Точность и полнота данной модели на достаточно хорошем уровне, но главное преимущество – это скорость. Создатели заявляют про 30кб в 1ms, на наших тестах питоновской обертки мы получили от 21 до 26кб в 1ms (70000-85000 сообщений в секунду, средний размер которых 0.8кб, а медиана – 0.3кб).
Данное решение очень простое в использовании. Для начала нужно установить его питоновскую обертку или воспользоваться нашим докером.
Чтобы сделать прогноз, достаточно просто импортировать библиотеку и написать одну дополнительную строчку кода:
Ответ детектора – это tuple из трех элементов:
- определился язык или нет;
- к-во символов;
- tuple из трех наиболее вероятных языков, где на первом месте идет полное название,
на втором – сокращение по стандарту ISO 3166 Codes, на третьем – процент символов пренадлежащих данному языку, на четвертом – к-во байт.
FastText
FastText – это библиотека написанная фейсбуком для эффективного обучения и классификации текстов. В рамках данного проекта фейсбук ресерч представил эмбеддинги для 157 языков, которые показывают state-of-the-art результаты на разных задачах, а также модель для определения языка и другие супервайзд задачи.
Для модели определения языка они использовали данные Wikipedia, Tatoeba and SETimes, а в качестве классификатора – свое решение на фасттексте.
Разработчики фейсбук ресерч предоставляют две модели:
- lid.176.bin, которая немного быстрее и точнее второй модели, но весит 128Мб;
- lid.176.ftz – сжатая версия оригинальной модели.
Для использования этих моделей в питоне, сначала нужно установить питоновскую обертку для фасттекста. Могут возникнуть сложности по ее установке, поэтому нужно внимательно придерживаться инструкции на гитхабе или воспользоваться нашим докером. А также необходимо скачать модель по вышеприведенной ссылке. Мы будем использовать оригинальную версию в данной статье.
Классифицировать язык с помощью модели от фейсбука немного сложнее, для этого нам понадобится уже три строки кода:
Модель FastText’a позволяет предсказывать вероятность для n-языков, где по дефолту n=1, но в этом примере мы вывели результат для топ-3 языков. Для этой модели это уже общая вероятность предсказания языка для текста, а не к-во символов, которые пренадлежат определенному языку, как было в модели cld2. Скорость работы тоже достаточно высокая – больше 60000 сообщений в секунду.
Обнаружение неизвестного языка с помощью Python
This module is a port of Google’s language-detection library that supports 55 languages. This module don’t come with Python’s standard utility modules. So, it is needed to be installed externally. To install this type the below command in the terminal.
Output:
Method 2: Using textblob library
This module is used for natural language processing(NLP) tasks such as noun phrase extraction, sentiment analysis, classification, translation, and more. To install this module type the below command in the terminal.(‘ru’, -641.3409600257874)
Example:
Output:
Method 3: Using langrid library
This module is a standalone Language Identification tool. It is pre-trained over a large number of languages (currently 97). It is a single.py file with minimal dependencies. To install this type the below command in the terminal.
Example:
Output:
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы. Для начала подготовьтесь к собеседованию
Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение — базовый уровень
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение — базовый уровень.
Google Переводчик
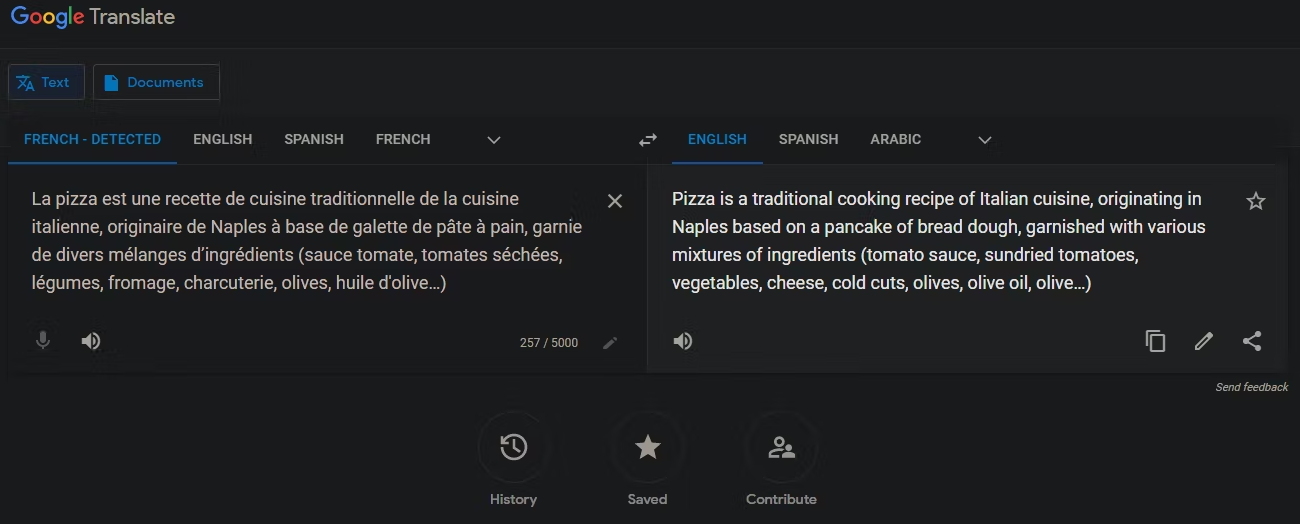
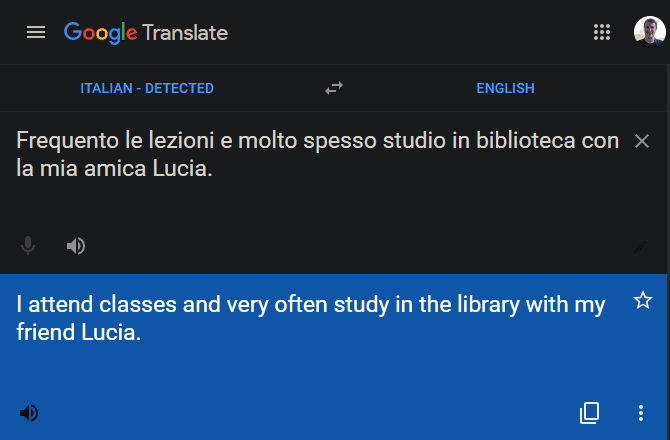
Возможно, вы уже использовали Google Translate.Но знаете ли вы, что у него есть функция «определить язык», которая позволяет работать с неизвестными языками?
Чтобы использовать его, скопируйте текст на неизвестном языке и перейдите в Google Translate.Вставьте текст в поле слева.Как только вы это сделаете, он должен определить язык вставленного текста с надписью -Detected и перевести его на английский для вас.
Если это не происходит автоматически, щелкните стрелку раскрывающегося списка над полем слева, чтобы отобразить все поддерживаемые языки.Здесь выберите язык обнаружения.Если вы хотите перевести обнаруженный текст на язык, отличный от английского, выберите другой язык в расширенном меню справа.
Это позволяет вам легко идентифицировать язык и видеть, что написано в тексте.Это отличный метод для любого текста, который вы сможете скопировать на свой телефон или компьютер.
Не забывайте, что Google Translate также предлагает множество интересных функций в своем мобильном приложении.Оттуда вы можете перевести рукописный текст или использовать камеру для перевода текста перед вами.Приложение даже имеет функцию транскрипции, которая переводит чей-то разговор в режиме реального времени, что может быть полезно, если вы хотите определить, о чем говорят поблизости.