
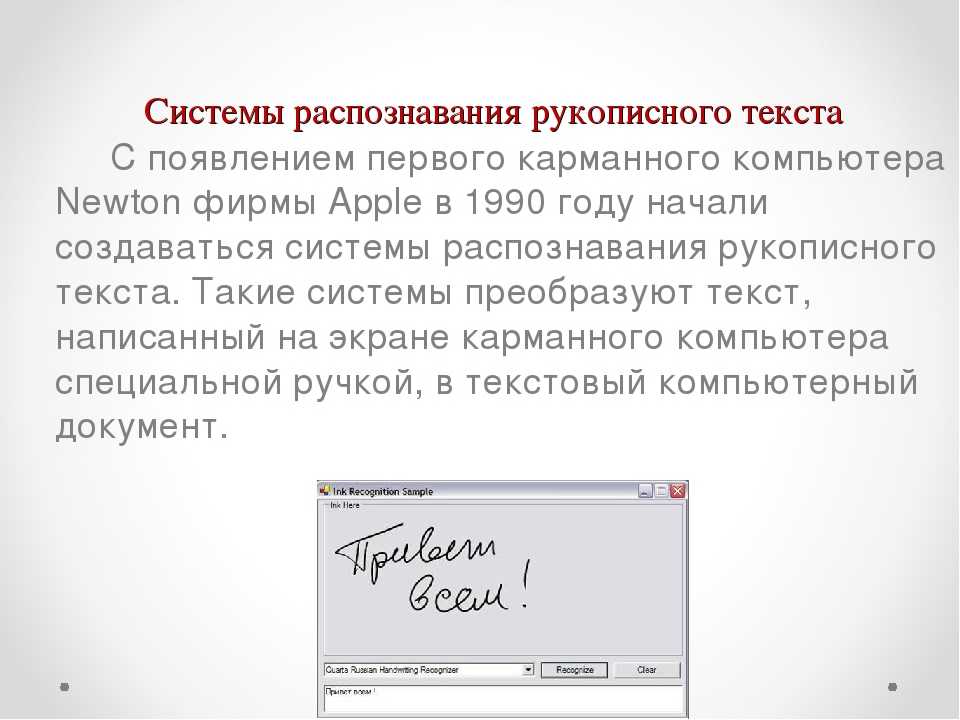
Используйте конвертер изображений в текст — Почему это важно?
Изображение в текст может сделать вашу жизнь очень комфортной, если вы будете использовать его в правильном направлении. Есть миллионы причин использовать этот инструмент. Некоторые из них:
Экономьте время и силы
С помощью этого инструмента вы можете сэкономить много времени. Когда доступна подходящая технология, оптимально использовать эту технологию для повышения производительности.
Для повышения производительности требуется больше времени, и с помощью этого инструмента вы можете сэкономить свое драгоценное время, получив текст за несколько секунд.
Развивайте свой бизнес
Этот инструмент абсолютно бесплатный. Итак, что мешает вам использовать этот лучший инструмент для развития вашего бизнеса и вывода его на новый уровень. Вы можете извлечь текст из всех своих деловых документов и сохранить его в одном месте. Эти данные можно использовать в дальнейшем для создания отчетов об анализе и проверках.
Извлечение контента из социальных сетей
Translate.yandex.ru с функцией OCR от компании Яндекс
известна своими качественными решениями в различных областях цифрового контента. Популярный ныне переводчик от Яндекса появился ещё в 2009 году, а в 2021 его каркас переведён на нейронную машинную основу, что повысило качество производимых им операций в несколько раз. Кроме непосредственной функции перевода, Яндекс.Переводчик имеет и функцию OCR, позволяющую выполнить распознавание текста на изображении онлайн, а затем и перевести данный текст на нужный пользователю язык. Качество распознавания на сервисе высокое.
Выполните следующее:
- Перейдите на translate.yandex.ru/ocr;
- Кликните на «Выберите файл», и укажите ресурсу путь к файлу изображения на вашем ПК;
- Картинка загрузится на ресурс, пройдёт процедура распознавания текста, после чего найденный текст будет отмечен желтоватым фоном;
- Далее у вас есть два пути распознанного текста.
Клик на надписи «Открыть в переводчике» откроет Яндекс.Переводчик, где в окне слева будет находиться распознанный иностранный текст, а в окне справа его русский перевод.
Нажатие на «Открыть в переводчике» откроет распознанный текст в Яндекс.Переводчик
Или вы сможете с помощью курсора пометить нужный вам текст, и вы сразу увидите его перевод рядом.
Шаг 3: Наложение прямой текст на изображениях с использованием OpenCV
Теперь мы хотим нарисовать прямоугольник вокруг каждого распознанного текстового элемента на своем исходном изображении. overay_ron_text () Функция будет объяснена задача задачи.
def overlay_ocr_text(img_path, save_name):
'''loads an image, recognizes text, and overlays the text on the image.'''
# loads image
img = cv2.imread(img_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
dpi = 80
fig_width, fig_height = int(img.shape/dpi), int(img.shape/dpi)
plt.figure()
f, axarr = plt.subplots(1,2, figsize=(fig_width, fig_height))
axarr.imshow(img)
Во-первых, мы используем модуль OPENCV для загрузки изображения в качестве Numpy Array и исправления его цветных каналов. Массив назначен переменной IMG Отказ Мы хотим отображать два изображения – исходное изображение и исходное изображение с распознанными текстами. подломы Способ MATPLOTLIB используется для отображения более одного рисунка за раз. Imshow Метод Аксар Переменная отображает исходное изображение.
# recognize text
result = recognize_text(img_path)
# if OCR prob is over 0.5, overlay bounding box and text
for (bbox, text, prob) in result:
if prob >= 0.5:
# display
print(f'Detected text: {text} (Probability: {prob:.2f})')
# get top-left and bottom-right bbox vertices
(top_left, top_right, bottom_right, bottom_left) = bbox
top_left = (int(top_left), int(top_left))
bottom_right = (int(bottom_right), int(bottom_right))
# create a rectangle for bbox display
cv2.rectangle(img=img, pt1=top_left, pt2=bottom_right, color=(255, 0, 0), thickness=10)
# put recognized text
cv2.putText(img=img, text=text, org=(top_left, top_left - 10), fontFace=cv2.FONT_HERSHEY_SIMPLEX, fontScale=1, color=(255, 0, 0), thickness=8)
распознать_text () Функция возвращает выход OCR и присваивает его Результат Переменная. А для Цикл создан для прохождения каждого текстового элемента, содержащегося в переменной. Признанные текстовые элементы отображаются только в том случае, если их уровни достоверности OCR выше 0,5 ( ZOB.5 ). Затем получены верхние левые и нижние правые вершины каждой ограничительной коробки. Они преобразуются на кортежи целочисленных ценностей (как требуется OpenCV).
Прямоугольник Способ создает зеленую ограничивающую коробку для каждого обнаруженного текстового элемента. PutText Метод отображает распознанный текст над его соответствующей ограничивающей коробкой. Как все это сделано в для петля, операция повторяется для каждого распознанного текста в Результат Переменная.
# show and save image
axarr.imshow(img)
plt.savefig(f'./output/{save_name}_overlay.jpg', bbox_inches='tight')
Наконец, overay_ron_text () Функция отображает каждый созданный текстовый и ограничивающий коробку. Imshow Метод Аксар Переменная отображает окончательное изображение. Поскольку обе левые, так и правые изображения находятся в одном Subplot, они отображаются как одно окончательное изображение. SaveFig Способ хранит окончательное изображение в определенный локальный каталог.
Преимущества использования оптического распознавания символов:
перевод текста по фото OCR бесплатно имеет следующие ключевые преимущества:
Помогает в поиске потерянных файлов:
Теперь немедленный доступ к потерянным PDF-файлам можно получить за пару кликов с помощью OCR-конвертера. В таком состоянии текст, который вы на самом деле ищете, спрятан где-то в файлах, и его удаление является действительно сложной и трудоемкой задачей. Но не волнуйтесь, так как технология OCR перевод текста по фото поможет вам найти перевести текст по фото и абсолютно за секунды.
Сделайте редактирование легким:
Вы не можете двигаться вперед, если не привыкли вносить изменения в свои контракты, документы и текстовые файлы в соответствии с новыми тенденциями в деловом мире. OCR помогает перевод текста по фото или любой другой файл мгновенно и отредактировать старый документ в новый, содержащий самую свежую информацию. Это означает, что вам не нужно создавать новый файл переводчик с фото текста с нуля, что является несомненным преимуществом технологии OCR.
Предотвращение человеческих ошибок:
Онлайн-технология OCR действительно помогает распознавать неправильные тексты или варианты написания в вашем документе. Как вы знаете, человеческие ошибки нельзя игнорировать, поэтому технология OCR позволяет свести на нет эти ошибки, создав текстовый файл, содержащий всю необходимую и точную информацию, которую вы ищете.
Экономит ваше драгоценное время и деньги:
Большинство компаний по всему миру по-прежнему застряли с огромными пачками бумажной работы. Это действительно очень раздражает, потому что работать с тяжелыми документами каждый раз непросто. Здесь в игру вступает технология оптического распознавания символов. Это помогает сканировать текст с изображений или документов и создавать файл мягкого текста. Этот файл не только легко редактируется, но вы также можете сохранить его в любом месте для будущего использования. Это уменьшит ваши общие инвестиции в бумажные документы и сэкономит вам много времени.
Экономит место:
Теперь попрощайтесь с бумажными пачками прямо сейчас! Да, теперь это может произойти быстро только благодаря технологии OCR. Теперь вы можете оцифровывать все свои драгоценные рукописные документы или информацию в инфографике изображений с помощью OCR скопировать текст с фото онлайн генератор и освобождать занимаемую площадь вашего офиса для других важных целей. Кроме того, вы также можете сэкономить много дополнительного времени, занимаясь ручным управлением листами бумаги в своем офисе.
Бонус: распознавание текста к речи
Выходы из OCR могут быть дополнительно используются с помощью простого приложения распознавания текстовой речи. Это преобразует текст в голосовое высказывание. Во-первых, нам нужно установить модуль PYTTSX3 следующим образом:
!pip install pyttsx3
Реализация может быть сделана в пять строк кода:
import pyttsx3
engine = pyttsx3.init()
engine.setProperty('rate', 100)
engine.say(sentence)
engine.runAndWait()
Код инициализирует двигатель TTS и назначает его переменного двигателя. SetProperty Метод определяет скорость высказывания. Скажи Метод регистрирует текстовое предложение, которое будет произносится. Наконец, Runandwait Способ выполняет операцию текстовой речи.
ABBYY Screenshot Reader
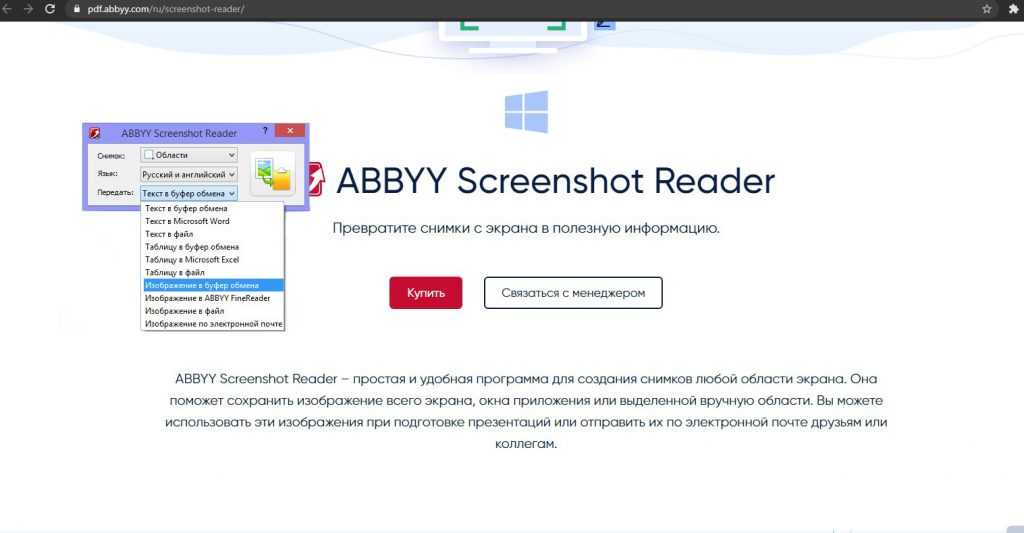
Отличие приложения ABBYY Screenshot Reader от предыдущего состоит в схеме распознавания. Если в FineReader вы просто загружаете документ и работаете, то в этой утилите все иначе – она просто считывает данные с экрана и преобразует их.
Работает Screenshot Reader в двух режимах – создании скриншотов и распознавании текста с экрана. Если вам нужно второе, сначала просто нажимаете на комбинацию клавиш, выбираете язык и принцип захвата, выделяете область, подтверждаете действие и ждете несколько секунд. Полученные данные сохранятся в выбранном вами формате. В приложение встроен словарь и переводчик, также другие полезные функции от компании ABBYY.
По умолчанию сервис распознает тексты на 5 языках – английском, русском, русско-английском, французском и немецком. Есть возможность добавления других языковых пакетов.
Плюсы
- Быстрый запуск посредством нажатия на комбинацию клавиш.
- Встроенная функция перевода и проверки орфографии.
- Есть запись экрана с функцией отсрочки.
- Распознавание текста с любого окна, даже в защищенном режиме.
- Создание скрина с любой, даже защищенной области экрана.
- Сохранение в нескольких форматах – rtf, txt, doc или xls.
Минусы
- Для копирования полученных данных в редактор нужно выделять материал вручную.
- Открыть файл через этот сервис не получится – только ручной захват экрана.
- Приложение не бесплатное. Есть бессрочная лицензия, но она стоит 1490 рублей. А срок действия пробной версии составляет всего лишь 7 дней, также в ней есть ограничение до 100 страниц.
Распознавание текста с картинки в OneNote
Стандартные программы офисного пакета Microsoft так же могут быть использованы для достижения вашей цели. Если вы не знали, в OneNote есть встроенное ПО для оптического распознавания печатных символов. Использовать его очень просто, вы можете убедиться в этом, продолжив чтение.
Шаг 1. Откройте свое изображение в любом средстве просмотра фотографий. Нажмите на кнопку печать.










Открываем фото и нажимаем печать
Шаг 2. В параметрах печати измените ваш принтер на программу OneNote.
Меняем принтер на программу OneNote
Шаг 3. Программа загрузится автоматически. В первую очередь выберите место расположения фотографии. Лучше всего использовать пустую страницу записной книжки, хотя это не принципиально.
Выбираем место расположение фотографии
Шаг 4. Теперь вы должны увидеть свое изображение вставленным в пустую страницу вашей записной книжки. Щелкните мышью по области изображения. В разделе «Поиск текста в рисунках» выберите русский, или любой другой в зависимости от текста, который необходимо распознать.
В разделе «Поиск текста в рисунках» выбираем необходимый язык
Шаг 5. Изменив язык распознавания, снова щелкните по изображению и воспользуйтесь одной из функций копирования текста.
Копируем текст
Шаг 6. Теперь вам нужно только лишь вставить выбранный текст в пустую область, и, если в этом будет необходимость, отредактировать его. Узнайте, как правильно отредактировать PDF документ в статье — «Как отредактировать PDF документ»
Вставляем текст
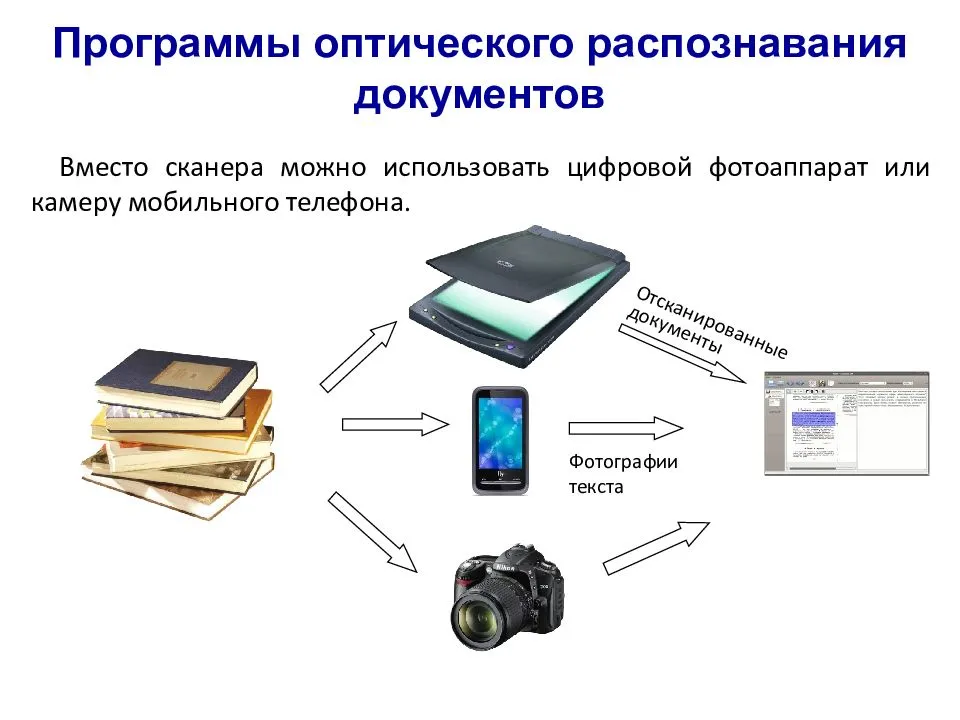
Как извлечь текст из изображений?
Извлечь текст из изображений довольно просто благодаря онлайн-инструменту преобразования точных изображений в текст. Вы можете получить текст из любого типа изображения.
Он может преобразовывать отсканированные изображения в текст, официальный документ, снимок экрана веб-страницы или любое случайное изображение, содержащее некоторые символы. Чтобы преобразовать изображение в текст с помощью указанного выше инструмента, выполните следующие действия:
Загрузите изображение с помощью кнопки «Загрузить изображение». Если вы хотите обрезать изображение, вы можете использовать наше обрезанное изображение
Если вы хотите преобразовать изображение в текстовый файл, используя URL-адрес из сервисов изображений, таких как Google Images, Pixabay , Pinterest или Shutterstock , просто вставьте URL-адрес.
- Нажмите кнопку «Отправить», чтобы преобразовать загруженные изображения в текст.
- Ура! Вы все правильно поняли.
- Вы получите текст в контейнере, из которого вы можете скопировать текст в буфер обмена, загрузить текст как файл .txt или сохранить его как документ.
- Если вы хотите преобразовать изображение, которое включает текст с других языков, вы можете выбрать другой язык на боковой панели.
Вы также можете конвертировать изображение PDF в текст онлайн с помощью этого инструмента.
Если вам интересно изображение или вы хотите отследить это изображение до его источника, вы можете использовать наш инструмент обратного поиска изображений , чтобы выполнить поиск по изображению.
Решение задачи с помощью OCR
Если вам нужно редактирование отсканированных документов, то воспользуйтесь любой программой OCR, функция которой заключается в оптическом распознавании символов. Данное ПО сравнивает символы в отсканированном файле с теми символами, которые имеются в его БД. После этого, программа данной категории производит конвертацию файла в удобный текстовый формат
Однако примите во внимание, что далеко не все OCR способны работать на бесплатной основе – среди них есть немало и платных вариантов. Также учтите, что в зависимости от того, насколько качественно вам удастся выполнить сканирование оригинала, вы можете столкнуться с различными ошибками, редактируя готовый скан
Чтобы решить непосредственно задачу связанную с тем, как редактировать сканированный текст следуйте следующей инструкции:
- Загрузите программу OCR с официального сайта разработчика или любого надежного веб-ресурса и установите ее.
- Откройте редактируемый файл в окне программы. Данный процесс может отличаться для каждого ПО подобного типа, но в целом от вас потребуется открыть файл, после чего запустить процесс конвертации. Во многих таких программах можно выбирать подходящий формат выходного файла. Главное, чтобы измененный тип документ был удобен для вас.
- После произведенной конвертации вам нужно будет удалить из готового файла форматирование, если с ним возникли какие-то проблемы. Дело в том, что ПО может учесть форматирование, к примеру, шрифты, межстрочные интервалы, если сканируемый файл отсканируется недостаточно ровно. Чтобы удалить форматирование используйте любой текстовый редактор, к примеру, обычный «Блокнот». Он, как правило, не способен распознавать форматирование, благодаря чему вставить текст в него можно без лишнего кода.
- В конце вам нужно открыть новый документ в любом удобном редакторе и приступить к такому процессу, как редактирование сканированных документов. Обязательно воспользуйтесь функцией проверки орфографии, чтобы вовремя найти все ошибки и устранить их. Но ошибки, связанные с форматированием, придется исправлять ручным образом.
Но прежде чем включить сканер и отсканировать тот или иной текст, вам стоит изначально определиться с удобной для вас программой оптического распознавания символов. Далее можно ознакомиться с одними из самых популярных и распространенных среди них:
- Одной из самых известных программ категории OCR, является ABBYY FineReader, работающая на платной основе. Данное ПО используется для конвертирования сканов в текстовые файлы с помощью запатентованных алгоритмов, которые позволяют распознавать даже текст, имеющий не очень высокое качество. В целом преимущества программы заключаются в высокой точности распознавания текста, способности преобразовывать всю структуру и внешний вид отсканированного текста. Следовательно, она оставит на своих местах не только текст, но также таблицы, рисунки и прочее.
- Readiris Pro — также является довольно распространенной программой с функцией OCR, которая обладает очень удобным интерфейсом. С ее помощью можно сохранить распознанный текст в таких форматах, как XPS, OpenOffice, PDF, Word и Excel. Следует добавить, что эта программа позволяет работать с более чем сотней языков мира и форматом DjVu.
- Freemore OCR представляет собой программу, распространяемую абсолютно бесплатно. С ее помощью можно достаточно оперативно извлекать графику и текст с отсканированных изображений. Извлеченный текст можно сохранить в виде документа Word. Помимо этого, она обладает функцией многостраничного распознавания. Но учтите, что интерфейс программы выполнен только на английском языке. Однако данное обстоятельство не влияет на удобство ее использования.
Abbyy Fine Reader
Это наиболее качественный и многофункциональный софт в данном ТОПе. Он отличается высокой точностью распознавания и имеет целый ряд преимуществ, распространяется платно.
Программа успешно работает со множеством языков, в ходе распознавания способна сохранять структуру текста и тип его форматирования.
Предназначена для профессионалов, потому, по мнению большинства пользователей, своих денет стоит.
Позитив:
- Высокое качество распознавания;
- Большое количество поддерживаемых языков;
- Способность сохранять стиль форматирования и особенности структуры документа достаточно точно;
- Наличие бесплатной пробной версии на 10 дней;
- Отсутствие снижения качества работы даже при больших объемах текста (что нередко наблюдается у других программ, которые хуже и хуже распознают текст с каждой последующей загруженной фотографии, и проблема устраняется только после перезапуска).
Негатив:
- Довольно значительная нагрузка на аппаратные ресурсы компьютера;
- Платное распространение по высокой стоимости при довольно коротком пробном периоде (всего на 10 дней);
- Замедление работы устройства при работе программы.
Особенности корректировки текстовых документов
Однако под редактированием может подразумеваться не только исключительно правка отсканированных документов, но и вообще любая корректура. Начнём с самого простого — удаления символов. Для этого предусмотрены клавиши Backspace и Delete. Первый вариант удаляет символ, стоящий слева от курсора мыши. Второй, соответственно, тот, что находится правее курсора.
Также нам может понадобиться отделить друг от друга отдельные абзацы для повышения общей читабельности. Используем для этой цели клавишу ввода Enter. Если мы хотим выполнить обратную процедуру, то занимаем место в самом начале второго абзаца. Нажатие кнопки Delete пододвинет второй абзац вплотную к предыдущему.
Ещё возникает потребность работать сразу с целым текстовым фрагментом. Например, нам нужно перенести кусок текста в другую часть документа. Для этого мы выделяем его левой кнопкой мышки. После этого делаем один щелчок правой её кнопкой. Из выпавшего перечня действий выбираем «копировать» или «вырезать». Переходим на то место, куда нужно перенести фрагмент. Клик правой кнопкой мыши — выбираем команду «вставить». Теперь текст переместится на новое место.
Во время набора текста обязательно случаются ошибки, а порой, сразу целая серия. В этой ситуации очень удобно отменить свои действия, чтобы не удалять вручную каждый неверный символ. Этот момент можно значительно упростить, если знать, как действовать. На главной панели вверху нужно найти стрелочку, показывающую обратное направление. Она может выглядеть по-разному в различных версиях Word. Или же воспользоваться горячей комбинацией клавиш «Ctrl+Z». Происходит отмена последнего набранного символа.








Может возникнуть потребность вставки в имеющийся текст специальных символов. Для этого в редакторе от Майкрософт предусмотрена «Вставка», а в ней ищем вкладку «Символы». Осталось лишь выбрать тот символ, который необходимо вставить, и он будет применён ко всему документу. Ещё один случай — заменить конкретное слово другим по всему тексту. Вручную делать это много раз очень долго, однако разработчики Word позаботились и упростили эту задачу. Сначала выбираем комбинацию Ctrl+H. После этого всплывает окошко, в котором нам предлагается выбрать то слово, что подлежит замене. В соседнем окошке указываем новое слово и нажимаем «применить».
Опция исправления ошибок позволит отредактировать не только орфографические ошибки, но и синтаксис. Редактор и сам подчеркнёт неправильную орфографию при помощи красной волнистой линии, а грамматические ошибки выделяются зелёной линией. Это существенно облегчает задачу пользователю, которому следует перейти в раздел с названием Рецензирование. После этого переходим во вкладку «Правописание». Редактор сам будет предлагать заменить неправильные слова или те, которых нет в предусмотренном словаре, на правильные.
При редактировании у пользователя появляется широкий выбор изменения шрифтов, которые находятся во вкладке с соответствующим названием. Их создано десятки видов, а некоторые даже в старинных стилях, наподобие готического, однако наиболее популярным является Times New Roman. Для работы выбирают различный размер шрифта, но более востребованными являются №№12 и 14. А готовый шрифт можно сделать жирным, отметить подчеркиванием, сделать курсивом.
Многим, кто работает с большими объёмами текстов по учёбе и работе, приходится делать нумерацию страниц в пределах одного документа. Для того чтобы пронумеровать их, перейдём во вкладку «Вставка», где предусмотрено немало интересных инструментов. Выберем «номер страницы», а затем место, куда будет проставлена нумерация на каждой из страниц документа. В большинстве случаев это бывает внизу посередине. Это основные функции, о которых следует знать начинающему редактору при работе с Word любой версии.
Convertio.co – ресурс для копирования надписей с изображений
Ресурс convertio.co – это популярный онлайн-конвертер, имеющий интернациональный характер. С его помощью можно провести конвертацию шрифтов, видео и аудио, презентации и архивы, изображений, документов. Доступна здесь и функция OCR, которой мы и воспользуемся. Бесплатно можно распознать 10 страниц (изображений), за большее количество придётся доплачивать.
Порядок действий:
- Запустите convertio.co/ru/ocr;
- Нажмите на «С компьютера» для загрузки изображения на ресурс;
- Чуть ниже выберите язык для распознавания (при необходимости активируйте дополнительные языки). Также выберите тип документа, в который будет трансформирован распознаваемый текст;
- Нажмите внизу на «Распознать»;
- Нажмите сверху на зелёную кнопку «Скачать» для получения результата;
Сервис Google Lens в телефонах
Во многих современных смартфонах уже есть встроенная функция Google объектив или Google Lens. Она позволяет перенести в текст символы на фотографиях или картинках в телефоне либо просто наведя камеру на объект с текстом.
Как перейти к этой функции:
- Включите в телефоне google ассистент, зажав центральную кнопку. А некоторых моделях может использоваться другая кнопка (например, питания)
-
Найдите внизу экрана значок, изображенный ниже и нажмите на него
- Далее наведите камеру на объект с текстом либо откройте фото из памяти устройства
Распознанный текст можно использовать следующими способами:
- Скопировать для дальнейшей вставки
- Поделиться им стандартными средствами телефона
- осуществить поиск в браузере используя найденные ключевые слова
Послесловие
Пакет Office представляет собой широкий набор инструментов для решения самых разнообразных задач. У каждой из входящих в него программ есть своя функциональность, и они дополняют друг друга при выполнении офисных работ. В частности, для редактирования отсканированных документов в Word потребуется программа распознавания, и в пакете она представлена. Такая структура «всё-в-одном» весьма удобна, так как не приходится думать, где найти и как установить сторонний софт, не нужно разбираться с особенностями его интерфейса: есть решения, выполненные в едином стиле. Поэтому Office был и остаётся стандартом де-факто для офисной работы.
Что же касается возможности вставить изображение напрямую в Word и редактировать его прямо оттуда, то пока что такой режим не поддерживается. Однако учитывая тенденции на объединение программ внутри пакета и уход в онлайн (мы имеем в виду Office365), стоит этого вскоре ожидать. Сейчас же нужно будет установить требуемый компонент (если он ещё не был установлен) и работать именно так.
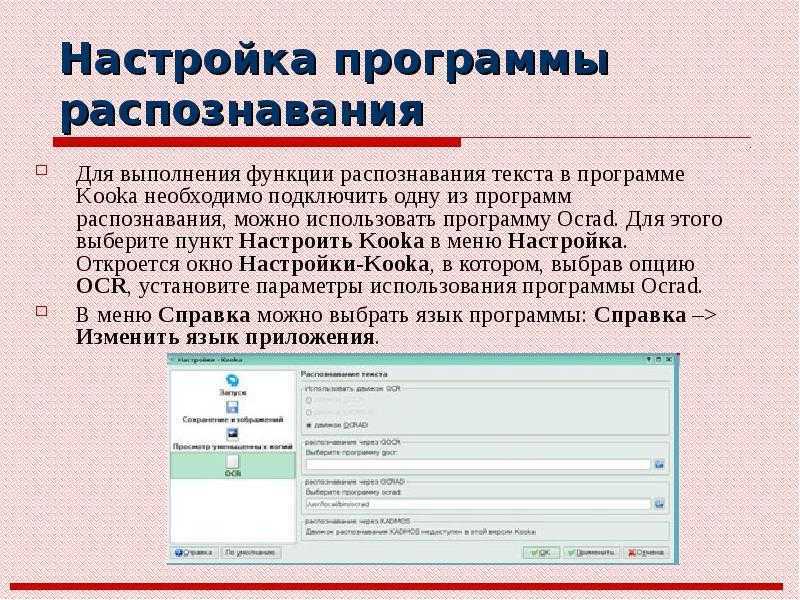
Scanitto
И последняя программа в нашем обзоре – Scanitto, которая может распознать текст с копий. С ее помощью можно объединить несколько файлов в один формата PDF или TIFF. Интерфейс Scanitto выполнен в виде альтернативного сканера. В нем можно захватывать определенные фрагменты через специальное оборудование, а затем импортировать выделенный материал в редактор.
В редакторе возможно выделять и помечать какие-то элементы, также разворачивать в нужном направлении. Программа распознает около 7 языков, в том числе русский. Готовый материал легко сохранить в формате bmp, jpeg, tiff, png, pdf или даже gif.
Плюсы
- Загрузка готового материала в различные онлайн-хранилища или социальные сети.
- Изменение разрешения изображения по усмотрению.
- Множество полезных функций для качественного распознавания текста.
- Недорогая лицензия. Если покупать на 1 компьютер, то она обойдется, грубо говоря, в 600 рублей, а в неограниченном варианте (который подойдет для организаций) стоимость составляет 6600 рублей.
- Подробная настройка параметров сканирования и копирования.
- Регулярные обновления программного обеспечения.
- Русскоязычный простой интерфейс.
Минусы
Ограничения в бесплатной версии. Ей можно пользоваться только в течение 30 дней.
На этом, пожалуй, обзор закончен. Выбирайте любую программу для распознавания текста на свое усмотрение, учитывая все возможные плюсы и минусы. Есть, конечно, еще различные онлайн-сервисы, но их надежность и качество сканирования оставляют желать лучшего.
Загрузка …
Post Views: 7 303
Бесплатные программы, считывающие текст
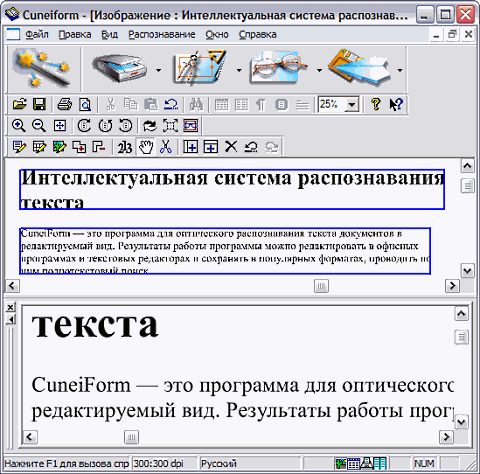
Есть бесплатные варианты. Например, CuneiForm, отличающаяся простотой и удобством. Необходимо скачать и установить на компьютер данный инструмент преобразования текста.
Одна из полезных программ — ABBYY FineReader
Рассмотрим подробнее перечень бесплатных (или условно бесплатных) программ с их возможностями, функциями и особенностями:
Программа, считывающая текст с картинки, — ABBYY FineReader 10. Она лидирует по популярности, что обусловлено качеством распознавания, четкостью обработки кириллицы. Хотя версии могут включать до 179 языков. Недостатком можно назвать факт, что бесплатный период пользования предоставляется лишь на 15 дней по пробной версии. При этом есть ограничение на считывание — до 50 страниц. FineReader справляется с картинками, имеющими пониженное (но не чрезмерно) качество. Если на изображении имеются буквы, программа точно распознает их.
OCR CuneiForm — бесплатная программа, считывающая текст с картинки. Точность несколько ниже, чем у FineReader. Имеется способность распознавать таблицы, текстовые блоки и изображения, сохранять шрифт, заложенный в достаточно обширной базе. Для пополнения словарного запаса подключаются словари
Программа справляется с ксерокопиями неважного качества. Недостатком является ограниченная точность, а также поддерживается не так уж много языков.
SimpleOCR может читать даже рукописи, но не имеет русского интерфейса и распознавания языка
Применяется для преобразования иностранных текстов. При этом удаляет «шум», имеет встроенный редактор.
Утилита WinScan2PDF не требует установки на компьютер и весит очень мало. При быстром распознавании сохраняет файлы лишь в PDF. Достаточно трижды нажать кнопки: выбирая источник, указывая место сохранения, для запуска процесса. Программа, считывая текст с картинки, быстро обрабатывает целые пакеты файлов. Интерфейс WinScan2PDF работает на многих языках. Скорость, портативность и простота — основные достоинства. К недостаткам относится результат, представленный в единственном формате.
Freemore OCR весьма оперативна, но не работает на русском языке. Имеет большую производительность, обслуживает несколько сканеров. Будучи бесплатной, программа не снабжена русским интерфейсом. А также нужно дополнительно загружать русскоязычный пакет для считывания текстов.
Большие текстовые объемы обычно обрабатываются специальными OCR-программами, считывающими текст с картинки, имеющими немалую стоимость.
Способы перевода текста по фотографии онлайн
Онлайн-сервисы удобны тем, что не требуют установки на компьютер. При этом перевод в них зависит от качества распознавания символов, на что влияют несколько факторов. Например, им сложно извлечь слова, написанные от руки или курсивом. Для них важна стабильная скорость интернет-соединения и достаточно четкие изображения. Тем не менее для периодического или одноразового использования этой функциональности будет достаточно.
Способ 1: Яндекс.Переводчик
Yandex Translate – популярный онлайн-ресурс для автоматического перевода текстов и web-страниц с функцией распознавания символов с картинок. Он полностью бесплатный и не требует регистрации. В его основе лежит гибридная система, объединяющая статистический и нейросетевой подход. Это позволяет делать сразу два варианта перевода, оценивать их с учетом ряда показателей и предлагать пользователю лучший.
- Заходим на сайт и открываем вкладку «Картинка».
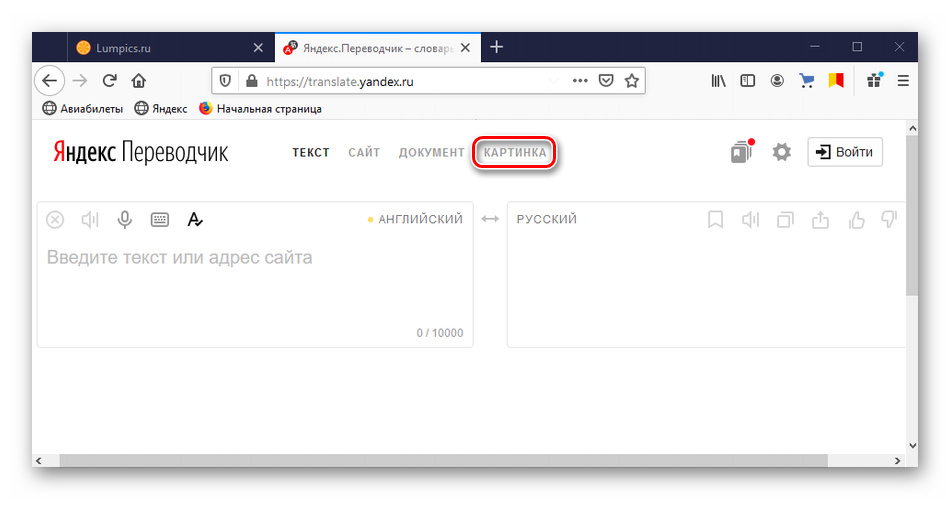
Выбираем язык текста на фотографии. Если он неизвестен, ставим галочку напротив пункта «Автоопределение».
Таким же образом выбираем язык перевода.
Нажимаем «Выберите файл», чтобы загрузить изображение. Или просто перетаскиваем его в рабочую область.
Находим на компьютере нужную картинку и кликаем «Открыть».
Когда сайт распознает текст, то выделит его желтым цветом. Щелкаем на любое слово и видим его перевод, либо выделяем все, и тогда сервис переведет их автоматически.
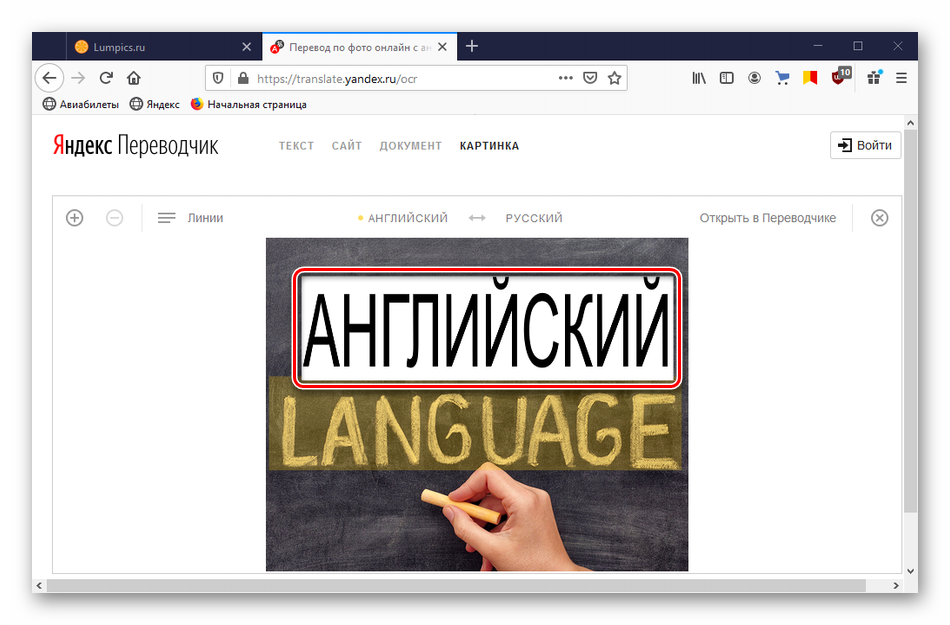
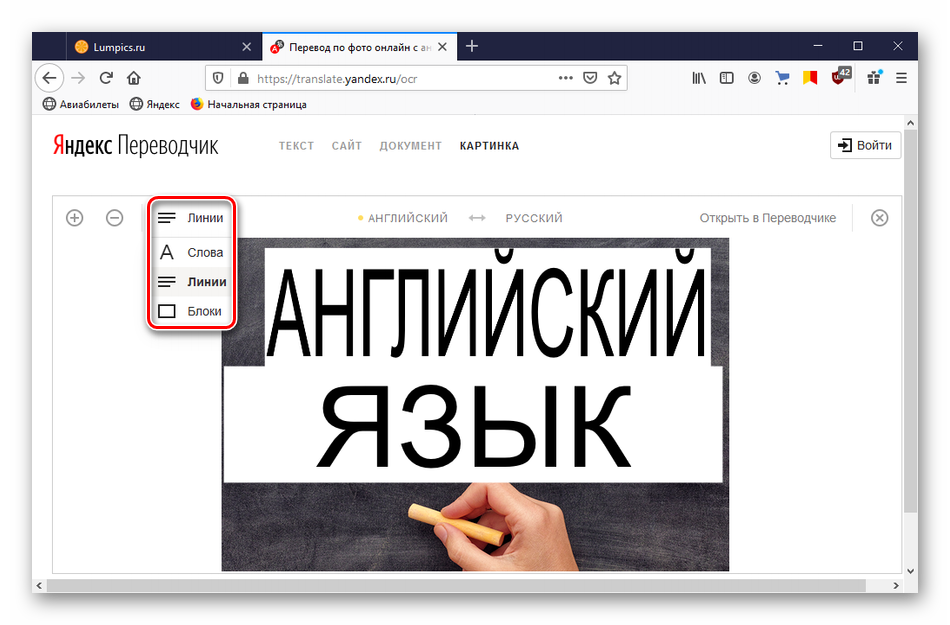
Жмем на иконку «Линии», чтобы настроить режим распознавания – по словам, по строкам, по предложениям.
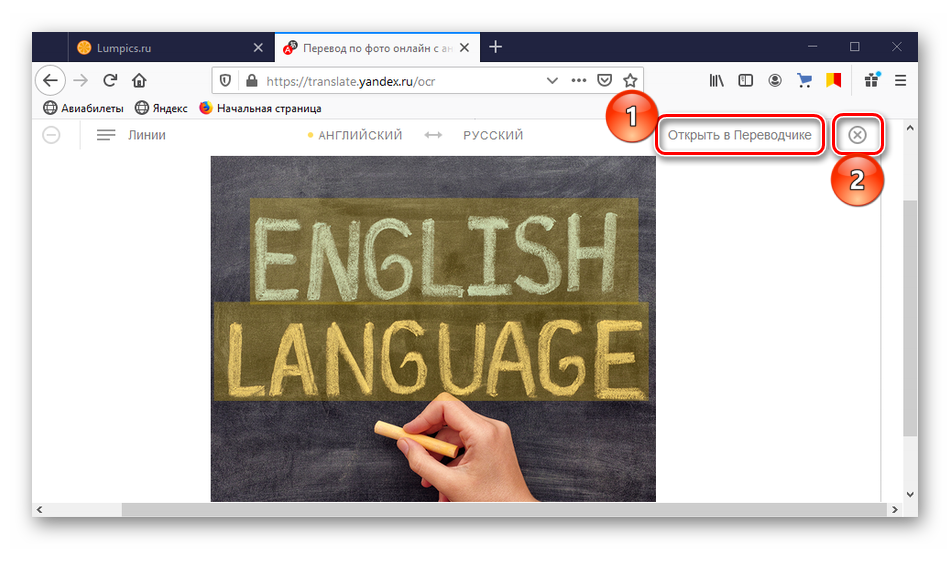
Чтобы отредактировать надпись или скопировать ее, нажимаем «Открыть в переводчике». Если нужно подгрузить другое изображение, жмем иконку «Очистить».
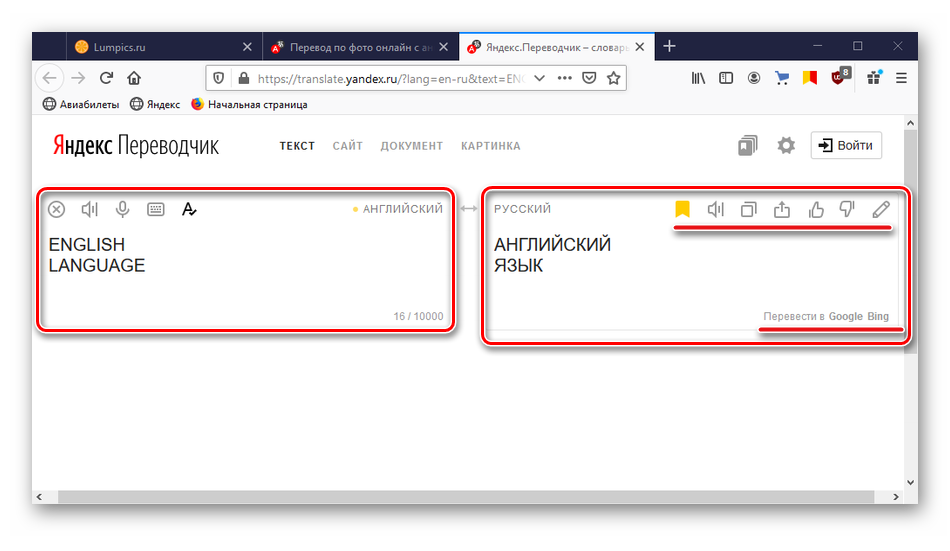
Сервис откроется в новой вкладке. Оригинал будет в левом, а перевод в правом блоке. С помощью панели управления сверху его можно скопировать, озвучить, оценить, сохранить или поделиться им. Ниже расположены ссылки на переводчики Google и Bing.
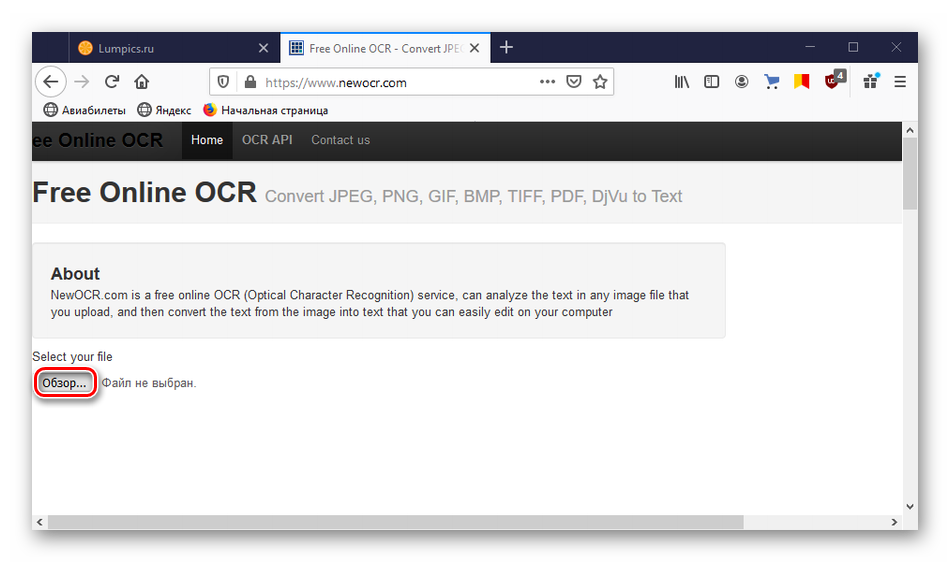
Способ 2: Newocr
Newocr – это сайт для распознавания текста без ограничений по количеству загрузок с функцией перевода с помощью Google Translate. В нем те же условия пользования, но он поддерживает больше входных форматов, включая загрузку многостраничных документов и ZIP-архивов из нескольких изображений.



- Открываем сервис и нажимаем кнопку «Обзор» для загрузки изображения.
Выбираем нужную картинку и жмем «Открыть».
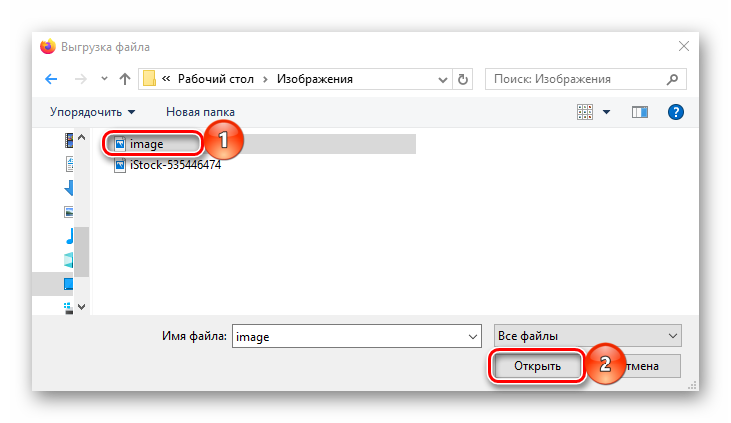
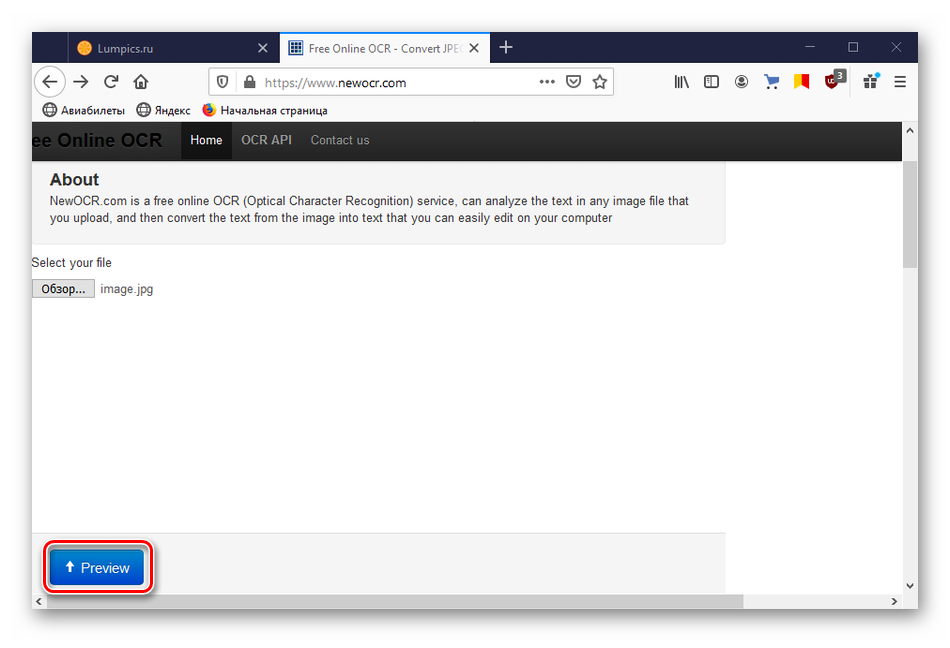
Жмем кнопку «Preview».
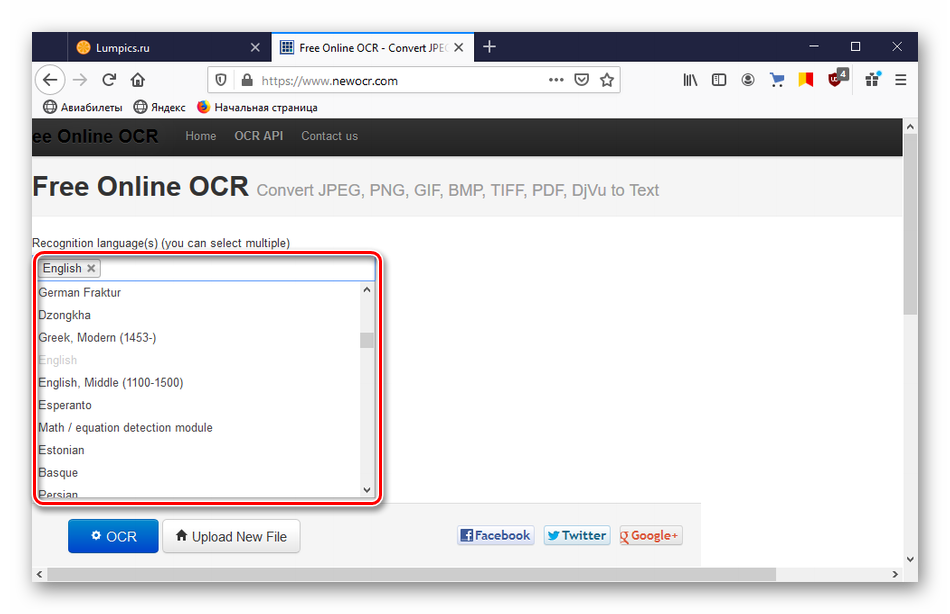
В верхнем поле указываем язык текста на картинке. Добавляем другие языки, если на изображении их несколько.
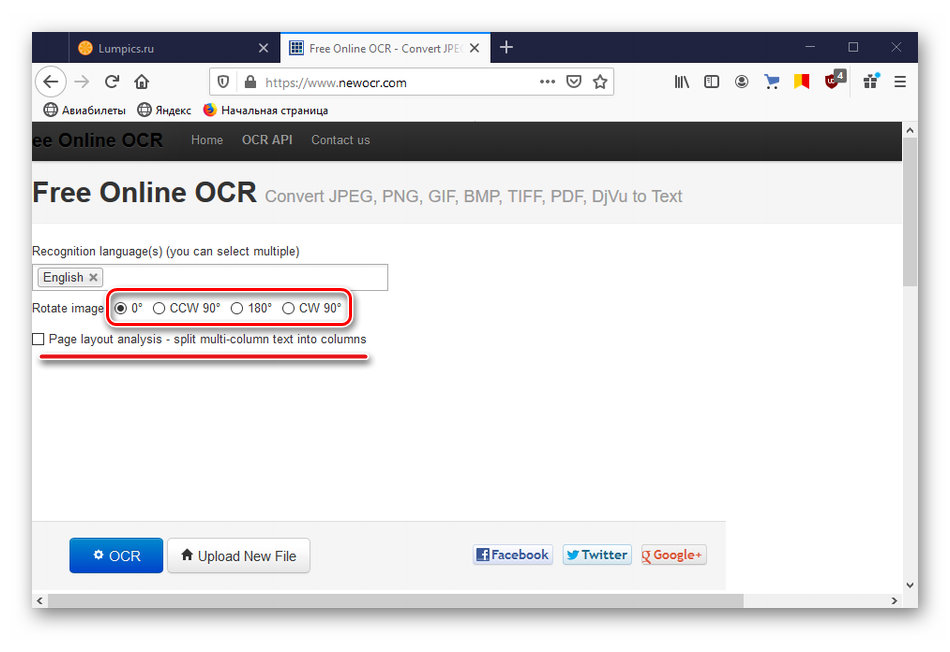
В блоке «Rotate image» можно повернуть изображение под определенным углом. Если поставить галочку напротив пункта «Page layout analysis», то многостолбцовый текст будет разбит на столбцы.
Чтобы увидеть изображение, опускаем полосу прокрутки вниз. Используя рамку, выделяем на изображении только область с текстом. Так сервису будет проще распознать символы.
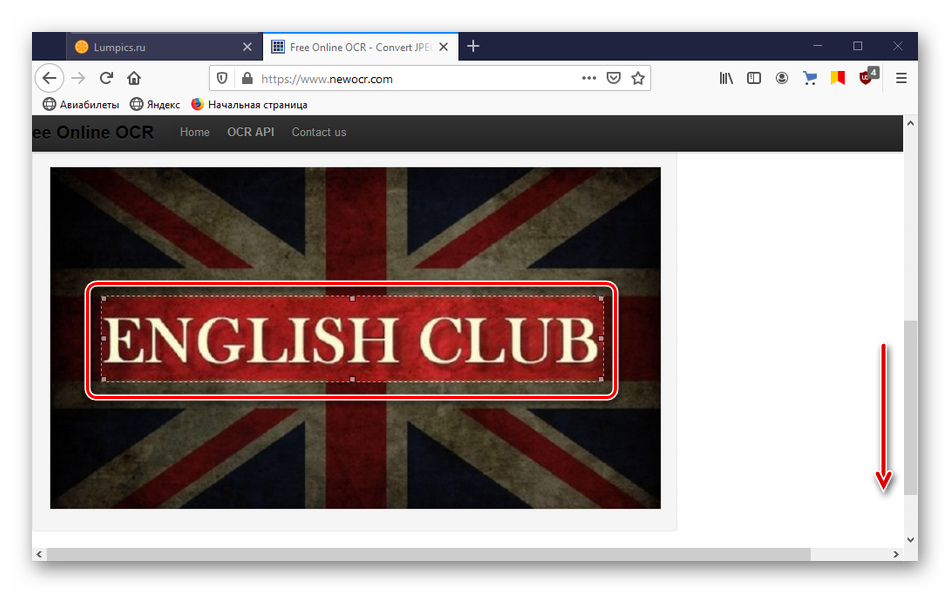
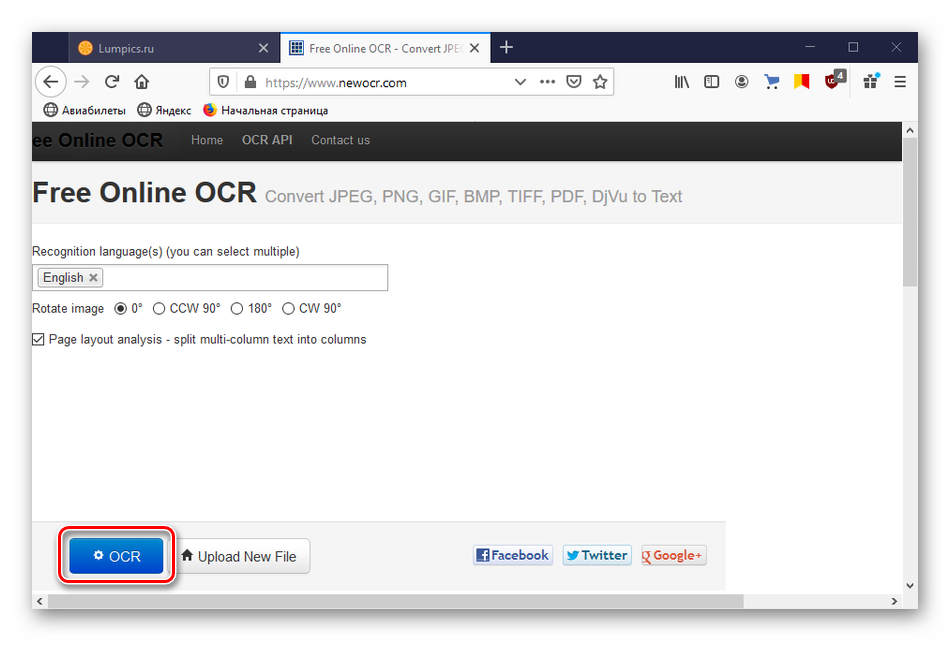
После всех настроек нажимаем кнопку «OCR». Чтобы загрузить новую фотографию, жмем «Upload new file».
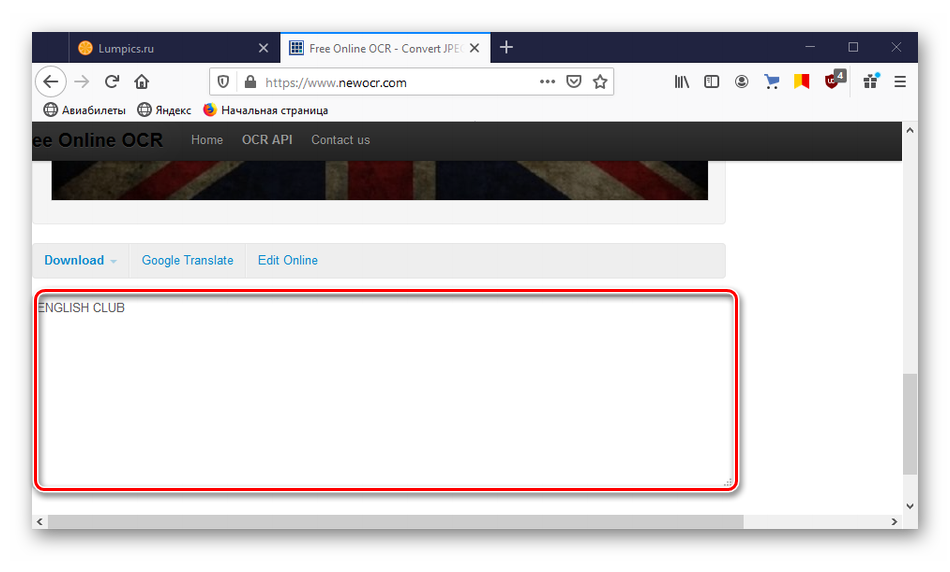
Распознанный текст находится внизу страницы.
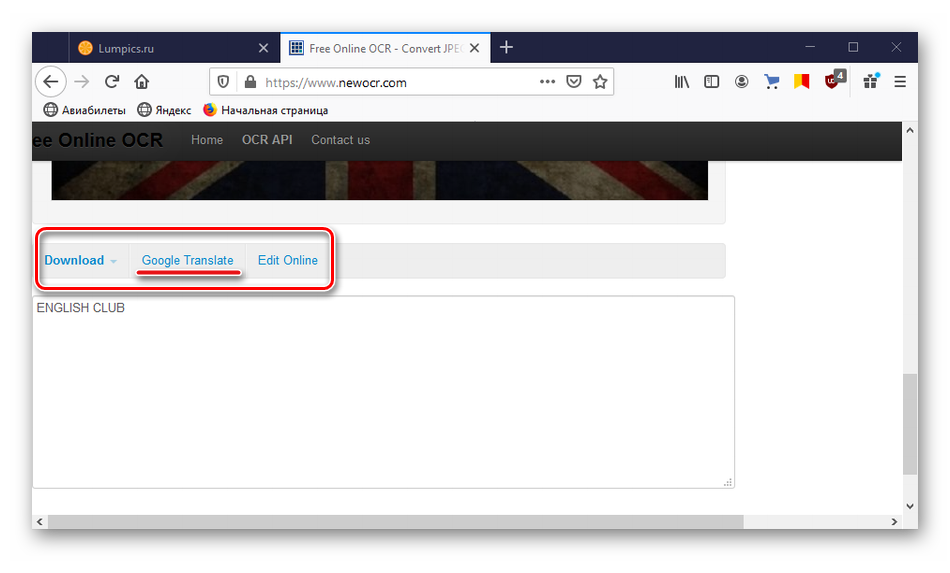
С помощью панели управления сверху можно сохранить надпись на компьютере в трех форматах (TXT, DOC, PDF), перевести ее или отредактировать. В данном случае кликаем «Google Translate».
В новой вкладке откроется переводчик Гугл с переведенным текстом.
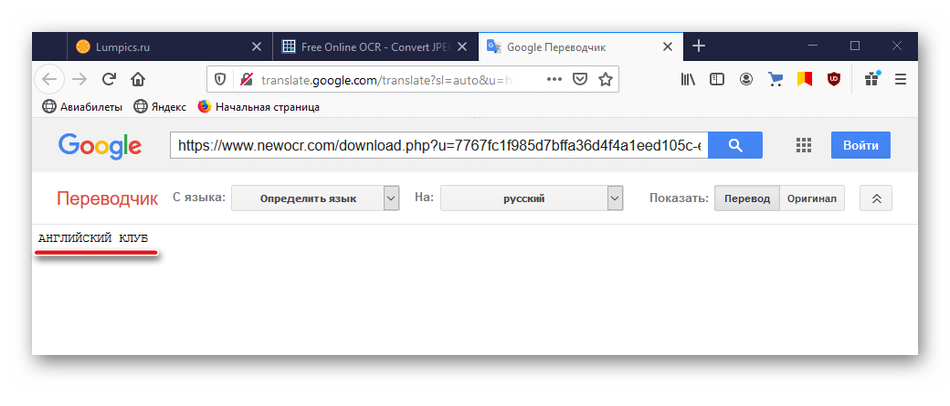
Сервис Newocr более чувствителен к распознаванию слов. Даже короткую фразу, написанную крупным шрифтом, он иногда представляет в виде набора случайных символов. В этом случае можно попробовать максимально отсечь лишнюю часть картинки выделительной рамкой, но это не всегда помогает.
Сайтов, способных сразу извлекать и переводить текст по фотографии, мало. Но есть и другие способы решения задачи. Пользователь может сначала загрузить картинку в любой сервис для оптического распознавания символов, которых достаточно много, а затем перевести текст в удобном для себя онлайн-переводчике.
Вывод
Если вы работаете с текстом постоянно и профессионально, то вам подойдет софт Abbyy Fine Reader.
Однако, если нужна именно бесплатная программа, то вполне удастся обойтись и OCR Cunei Form.
Для простой и быстрой работы со скриншотами скачайте Abbyy Screenshot Reader, но строго говоря, без этой программы вообще можно обойтись.
Если распознавание – только одна, и не самая частая задача при вашей работе с документами, то отдайте предпочтение многофункциональной Adobe Acrobat, способной заменить множество программ.
Если де необходимость в распознавании единична, то используйте Free Online OCR.