
I нормальная форма
Нормализация
отношений выполняется на основе анализа первичных ключей и существования
функциональных зависимостей между атрибутами. Как правило, нормализация
выполняется в несколько этапов. Каждый этап соответствует определенной
«Нормальной форме» (НФ). При проектировании реляционных БД требования 1-ой НФ
должны выполняться всегда, остальные по желанию проектировщика. Однако, чтобы
исключить аномалии обновления и избыточностиданных рекомендуется приводить отношение к 3-ей НФ.
Ненормализованное
отношение приводится к 1-ой НФ следующими способами:
—
Выравнивание таблиц или добавление строк;
—
Один атрибут или группа атрибутов, которые назначены ключомотношения повторяющейся группы помещается
вместе с ключом в отдельные отношения. Во вновь созданных отношениях
устанавливаются свои первичные ключи.
Нормальные формы.
Правила нормализации, применяемые к таблице, уменьшают проблемные области, «поднимая» таблицы на более высокий уровень согласованности данных, особенно в процессе добавления, обновления и удаления записей. Первая нормальная форма (1NF) — является первым правилом, вторая — вторым и тд. Давайте рассмотрим эти правила подробнее.
Первая нормальная форма (1NF)
Первая нормальная форма основана на атомарности значений полей в таблице. Имеется ввиду, что в поле должна храниться только какая-либо одна сущность. Например, в представленной ниже таблице к записи о сотруднике «привязано» несколько телефонных номеров. Это результат ошибок в проектировании.
Вместо этого, мы должны разместить данные в таблице следующим образом:
В результате мы получили много записей со значением NULL, более того, мы не можем добавить другой номер телефона. Лучше разделим эту таблицу на 2, так, как показано ниже.
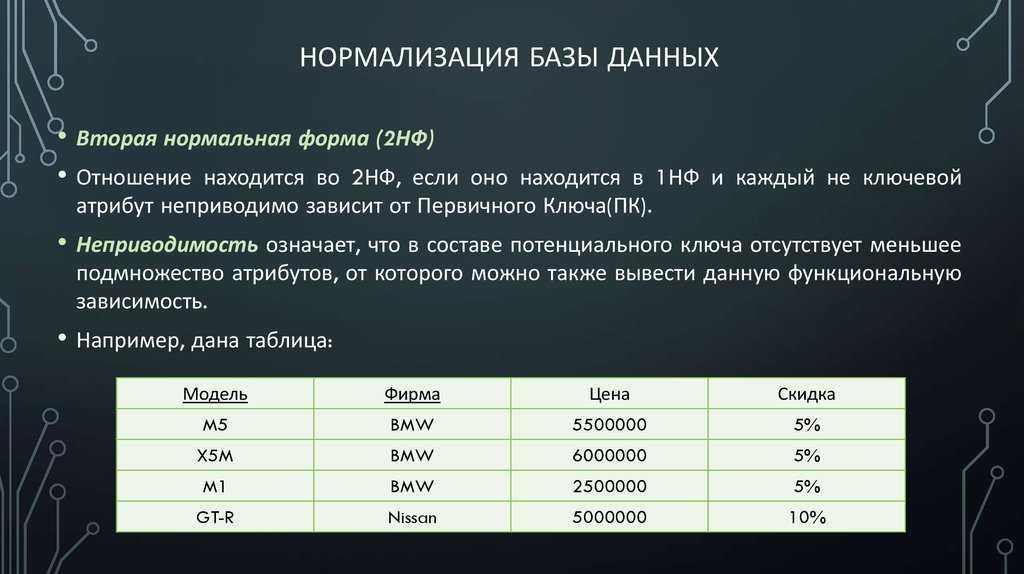
Вторая нормальная форма (2NF)
Вторая нормальная форма основана на идее полной функциональной зависимости, при условии, что таблица находится в первой нормальной форме (1NF). Сейчас нужно удалить все не ключевые значения, которые не имеют полной зависимости от значения первичного ключа. Например:
В таблице выше, существуют следующие зависимости:
{SSN} → {EMPLOYEE_NAME}{SSN} → {PROJ_HOURS}
Также,
{PROJECT_NO} → {PROJECT_NAME}{PROJECT_NO} → {PROJECT_HOURS}
Это грубое нарушение 2NF, потому что значение полей PROJECT_HOURS и PROJECT_NAME в каждой записи функционально зависимы от PROJECT_NO. Кроме того, EMPLOYEE_NAME и PROJ_HOURS однозначно определяются значением поля SSN. Чтобы привести данные к 2NF в данном случае мы можем «разложить» таблицу EMPLOYEE_PROJECT на несколько таблиц:
Третья нормальная форма (3NF)
Чтобы привести таблицу в третью нормальную форму (3NF), она должна находится во второй нормальной форме (2NF) и, самое главное, не должна содержать данные с транзитивными зависимостями. Транзитивная зависимость — это случай, когда X→Y, Y→Z, X→Z. Это значит, что любое не ключевое поле не должно быть зависимо от поля, которое не является первичным ключом таблицы. Например:
Здесь, существуют зависимости:
{SSN} → {EMPLOYEE_NAME}
{SSN} → {BIRTH_DATE}
{SSN} → {DEPT_NAME}
{SSN} → {DEPT_ADDRESS}
Однако, аномальной является следующая зависимость:
{DEPT_NAME} → {DEPT_ADDRESS}
потому что DEPT_NAME не является ключом. Мы можем устранить эту проблему, разделив таблицу на 2 таблицы.
Нормальная форма Бойса-Кодда (BCNF)
В большинстве случаев, BCNF — это эквивалент 3NF. Правда эта форма строже, чем третья нормальная форма. Любая таблица, находящаяся в BCNF, находится в 3NF, но не наоборот.
BCNF — это нетривиальная функциональная зависимость X→Y в которой X, находящийся в ее левой части, является первичным ключом.
Давайте разберемся в этом на примере нескольких таблиц. Некоторые из них находятся одновременно и в 3NF и в BCNF, другие же находятся в3NF, но не в BCNF.
{SSN} → {EMPLOYEE_NAME}
{SSN} → {BIRTH_DATE}
В таблице EMPLOYEE первичным ключом является поле SSN. Это нетривиальная функциональная зависимость, таблицы EMPLOYEE, в левой части которой находится атрибут SSN. Так как SSN является первичным ключом, функциональная зависимость не нарушает условий BCNF.
{PROJECT_NO} → {PROJECT_NAME}
{PROJECT_NO} → {PROJECT_DURATION}
Таблица PROJECT также находится в BCNF.
{DEPT_NO, SSN} → {PROJECT_NO, DURATION}
{PROJECT_NO} → {DURATION, DEPT_NO}
Однако, PROJECT_INFO не находится в BCNF, потому что PROJECT_NO не является первичным ключом. Не может быть пары строк, представляющих 2 разных SSN, работающих в том же PROJECT_NO и DEPT_NO. Например:
Функциональная зависимость PROJECT_NO → DURATION нетривиальна. Таким образом, таблица не удовлетворяет определению BCNF. Мы можем устранить эту проблему, если перепроектируем эту таблицу таким образом, чтобы все полученные в результате таблицы приняли BCNF. Например:
3НФ — третья нормальная форма
Что такое транзитивная зависимость легко понять на примере уже упоминавшейся выше таблицы продаж — типичного примера ассоциативной таблицы.
Предположим, что продажа каждой товарной позиции имеет своим основанием документ (заказ, счёт и т.д.), а её стоимость характеризуется ценой, количеством и валютой. В этом случае имеем следующие зависимости между атрибутами (колонками):
- «Идентификатор продажи» => «Номер документа»
- «Идентификатор продажи» => «Код валюты»
- «Номер документа» => «Код валюты»
Эти зависимости транзитивны: каждая продажа однозначно определяет свой документ-основание и расчётную валюту, однако, валюта определяется ещё и документом.
Результатом нарушения 3НФ является избыточность хранения и необходимость обновления данных в связанной таблице. Так, если вы оставите колонку «Код валюты» в таблице продаж, то при изменении валюты документа придётся также обновлять все связанные с ним строки продаж.
Функциональная зависимость
Реляционная БД содержит семантическую и структурную информацию. Структурой БД определяет число и вид включенных в нее отношений и связи типа «один-ко-многим», которые существуют между кортежами этих отношений. Семантической частью описывается множество функциональных зависимостей, которые существуют между атрибутами этих отношений.
Определение 1
Если имеются два атрибута А и В какого-либо отношения, то говорят, что В функционально зависит от А, если в каждый момент времени каждому значению А соответствует лишь одно значение В.
Функциональную зависимость (ФЗ) обозначают $А \to В$
Обратим внимание, что А и В могут быть не только единичными атрибутами, но и группами, которые составлены из нескольких атрибутов одного отношения
Говорят, что функциональные зависимости являются связями типа «один-ко-многим», которые существуют внутри отношения.
С помощью функциональных зависимостей можно накладывать на реляционную схему дополнительные ограничения. Основной идеей является то, что значением одного атрибута в кортеже однозначно определяется значение другого атрибута.
К примеру, в каждом кортеже на рисунке 1 Фамилия однозначно определяется № работника; Специальность однозначно определяется № работника. Данные функциональные зависимости записывают в виде:
ФЗ: № работника $\to$ фамилия,
ФЗ: № работника $\to$ специальность.
Определение 2
Функциональная зависимость значением одного атрибута в кортеже однозначно определяет значение другого атрибута в кортеже.
Другими словами функциональная зависимость определяется следующим образом:
Определение 3
Если в таблице R существуют атрибуты А и В, то запись
ФЗ : $A \to В$
значит, что при одном и том же значении атрибута А двух кортежей в таблице R они будут иметь одно и то же значение атрибута В.
Знак $\to$ читают «функционально определяет».
Данное определение можно применить также в случае, когда А и В являются множеством столбцов, а не просто отдельными столбцами.
Определение 4
Детерминантом называют атрибут в левой части функциональной зависимости, т.к. его значением однозначно определяется значение атрибута в правой части.
Детерминантом всегда является ключ таблицы, т.к. его значением однозначно определяется значение каждого атрибута таблицы.
Проецирование функциональных зависимостей
Декомпозиция отношений по сути осуществляется при помощи операции проекции. При этом, мы утверждаем, что функциональные зависимости при декомпозиции сохраняются. Возникает вопрос: каким образом функциональные зависимости ведут себя при проецировании отношений?
Предположим, что имеется исходное отношение \(R\) с множеством ФЗ \(F\), и пусть \(S\) – некая проекция отношения \(R\): \ где A – некое множество атрибутов.
Тогда, множество \(G\) ФЗ, которые останутся в \(S\), это ФЗ, которые:
- Следуют из \(F\)
- Включают только атрибуты, принадлежащие \(A\)
Вполне вероятно, что множество всех ФЗ такого рода избыточно (не минимально). Сложность алгоритма поиска ФЗ отношения \(S\) в худшем случае экспоненциально зависит от количества атрибутов в \(A\).
Для нахождения всех ФЗ можно применять замыкание атрибутов из \(A\) по \(F\). Следует сделать два достаточно очевидных замечания:
- Замыкания пустого множества и множества всех атрибутов не приводят к получению нетривиальных ФЗ
- Если \(A \subset X^+\), то построение замыканий для надмножеств \(X\) не даст новых нетривиальных ФЗ в силу правила дополнения.
Так же понятно, что для любого замыкания \(X^+\), существуют ФЗ вида \(X \to B\), где \(B \subset X^+\).
Таким образом, мы можем начать с построения замыканий для единичных множеств атрибутов, и добавить все следующие из них ФЗ к множеству ФЗ \(G\), если они содержат только атрибуты из \(A\), а затем, при необходимости, построить замыкания для множеств атрибутов большей размерности.
Пример:
Пусть отношение \(R(A,B,C,D)\) имеет следующие ФЗ:
- \(A \to B\)
- \(B \to C\)
- \(C \to D\)
Пусть теперь мы получаем проекцию \(S = \pi_{A,C,D} R\). Найдем ФЗ \(G\) отношения \(S\).
Для этого, построим замыкания для всех атрибутов отношения \(S\) по \(F\). Поскольку \(B\) не входит в отношение \(S\), его замыкание не даст нам ФЗ, входящих в \(G\). \ \ \
Можем заметить, что \({A,C,D} \subset {A}^+\), соответственно, рассмотрение надмножеств \({A}\) не имеет смысла. Следовательно, единственное неединичное множество атрибутов, требующее рассмотрения это \
Запишем множество нетривиальных ФЗ \(S\), получающиеся из этих замыканий: \ \ \
Теперь найдем минимальное множество ФЗ. По правилу транзитивности, ФЗ \(A \to D\) следует из двух других, поэтому его можно исключить. В итоге, получаем минимальное множество ФЗ \(S\): \ \
Обзор процесса нормализации
Процесс нормализации отношения
заключается в преобразовании ненормализованных отношений к требуемому уровню
НФ. Рассмотрим последовательно весь процесс нормализации до НФ БК.
Результаты проверки
объектов недвижимости
|
N_объекта |
Адрес |
Дата |
Время |
Комментарий |
N_сотрудника |
ФИО_сотредника |
N_маш |
|
01 |
Ленина 6-31 |
8,01,03 22,11,03 15,04,04 |
10:00 20:00 12:00 |
Требуется ремонт |
37 311 312 |
Лис Крот Кот |
03-12 07-11 21-13 |
|
02 |
…… |
…… |
…… |
…… |
…… |
…… |
…… |
Первый этап НФ – приведем к
НФ. Для этого добавим новые строки. Определим потенциальные клюю отношения:
(N_объекта, Дата)
(N_сотрудника, Дата, Время)
(N_маш, Дата, Время)
Второй этап – приведение
отношения ко 2-ой НФ. Для этого выписываются функциональные зависимости и
устраняются частичные функциональные зависимости.
f1: N_объекта,
Дата -> Время, Комментарий, N_сотрудника,
ФИО_сотрудника, N_маш
f2: N_объекта
-> Адрес
f3: N_сотрудника
-> ФИО_сотрудника(транзитивная
зависимость)
f4: N_сотрудника,
Дата -> N_маш(частичная зависимость)
f5: N_маш,
Дата, Время -> N_объекта,
Адрес(для потенциальных ключей)
f6: N_сотрудника,
Дата, Время -> N_объекта,
Адрес, Комментарий.
Что бы привести отношение ко 2-ой
НФ его необходимо будет разбить на три отношения:
Объект ( N_объекта,Адрес)
Сотрудник (N_сотрудника, ФИО_сотрудника)
Проверка (N_объекта, Дата, Время, Комментарий, N_сотрудника, N_маш)
Полученное отношениеудовлетворяет не только 2-ой НФ, но и 3-ей
НФ.
Третий этап – проверка
принадлежности отношений к НФ БК. Отношение «Объект» и «Сотрудник»
удовлетворяют НФ БК. Отношение «Проверка» не удовлетворяет НФ БК,
посколькудетерминант (N_сотрудника, Дата), который не является
потенциальным ключом. Потому отношение «Проверка» может страдать аномалией
обновления, т.е. при изменение данных об автомобиле придется вносить изменения
сразуже в нескольких отношениях. Для
этого отношение «Проверка» необходимо разбить на отношения:
Сотрудник – Машина
(N_сотрудника, N_маш, Дата)
Проверка – Дата
(N_объекта, Время, Комментарий, N_сотрудника)
Четвертый этап – отношение многозначных
зависимостей,которые позволяют
избавиться от избыточности.
Избегайте переходных зависимостей, чтобы помочь обеспечить нормализацию
Транзитивная зависимость в базе данных – это косвенная связь между значениями в одной и той же таблице, которая вызывает функциональную зависимость. Чтобы достичь стандарта нормализации третьей нормальной формы (3NF), вы должны устранить любые переходные зависимости.
По своей природе транзитивная зависимость требует трех или более атрибутов (или столбцов базы данных), которые имеют функциональную зависимость между ними, что означает, что столбец A в таблице опирается на столбец B через промежуточный столбец C. Давайте посмотрим, как это может работать.
Пример транзитивной зависимости
АВТОРЫ
| Auth_001 | Орсон Скотт Кард | Игра Эндера | Соединенные Штаты |
| Auth_001 | Орсон Скотт Кард | Игра Эндера | Соединенные Штаты |
| Auth_002 | Маргарет Этвуд | История о горничной | Канада |
В примере АВТОРЫ выше:
- Книга → Автор : . Здесь атрибут Книга определяет атрибут Автор . Если вы знаете название книги, вы можете узнать имя автора. Однако Автор не определяет Книгу , поскольку автор может написать несколько книг. Например, только потому, что мы знаем имя автора Орсон Скотт Кард, мы до сих пор не знаем название книги.
- Автор → Author_Nationality : Аналогично, атрибут Author определяет Author_Nationality , но не наоборот; только то, что мы знаем национальность, не означает, что мы можем определить автора.
Но эта таблица вводит транзитивную зависимость:
Книга → Author_Nationality: Если мы знаем название книги, мы можем определить национальность через столбец Автор.
Избежание переходных зависимостей
Чтобы обеспечить третью нормальную форму, давайте удалим транзитивную зависимость.
Мы можем начать с удаления столбца Book из таблицы Authors и создания отдельной таблицы Books:
Книги
| Book_001 | Игра Эндера | Auth_001 |
| Book_001 | Дети разума | Auth_001 |
| Book_002 | История о горничной | Auth_002 |
АВТОРЫ
| Auth_001 | Орсон Скотт Кард | Соединенные Штаты |
| Auth_002 | Маргарет Этвуд | Канада |
Это исправило это? Давайте рассмотрим наши зависимости сейчас:
Стол BOOKS .
Book_ID → Книга: Книга зависит от Book_ID .
Других зависимостей в этой таблице не существует, поэтому мы в порядке
Обратите внимание, что внешний ключ Author_ID связывает эту таблицу с таблицей AUTHORS через ее первичный ключ Author_ID. Мы создали отношения, чтобы избежать транзитивной зависимости, ключевого дизайна реляционных баз данных.
Таблица АВТОРОВ .
Нам нужно добавить третью таблицу для нормализации этих данных:
Страны
| Coun_001 | Соединенные Штаты |
| Coun_002 | Канада |
АВТОРЫ
| Auth_001 | Орсон Скотт Кард | Coun_001 |
| Auth_002 | Маргарет Этвуд | Coun_002 |
Теперь у нас есть три таблицы, использующие внешние ключи для связи между таблицами:
- Внешний ключ таблицы BOOK Author_ID связывает книгу с автором в таблице AUTHORS.
- Внешний ключ таблицы AUTHORS Country_ID связывает автора со страной в таблице COUNTRIES.
- Таблица COUNTRIES не имеет внешнего ключа, поскольку в этом дизайне нет необходимости ссылаться на другую таблицу.
Почему транзитивные зависимости плохой дизайн базы данных
Какова ценность избегания транзитивных зависимостей, чтобы помочь обеспечить 3NF? Давайте снова рассмотрим нашу первую таблицу и посмотрим на проблемы, которые она создает:
АВТОРЫ
| Auth_001 | Орсон Скотт Кард | Игра Эндера | Соединенные Штаты |
| Auth_001 | Орсон Скотт Кард | Дети разума | Соединенные Штаты |
| Auth_002 | Маргарет Этвуд | История о горничной | Канада |
Такая конструкция может способствовать аномалиям и несоответствиям данных, например:
- Если вы удалили две книги «Дети разума» и «Игра Эндера», вы полностью удалили из базы данных автора «Карту Орсона Скотта» и его гражданство.
- Вы не можете добавить нового автора в базу данных, если вы также не добавите книгу; Что делать, если автор еще не опубликован или вы не знаете название книги, которую она написала?
- Если «Орсон Скотт Кард» изменил свое гражданство, вам придется изменить его во всех записях, в которых он появляется. Наличие нескольких записей с одним и тем же автором может привести к получению неточных данных: что, если лицо, занимающееся вводом данных, не понимает, что для него существует несколько записей, и изменяет данные только в одной записи?
- Вы не можете удалить такую книгу, как «Сказка о служанке», не удалив также полностью автора.
Это всего лишь несколько причин, по которым нормализация и избежание транзитивных зависимостей защищают данные и обеспечивают согласованность.
Инфологическое проектирование
- Инфологическое проектирование
- построение семантической модели предметной области, то есть информационной модели наиболее высокого уровня абстракции.
Такие модели, как правило, строятся без ориентации на конкретную СУБД или даже модель данных. Смысл построения инфологической модели заключается в выделении основных сущностей предметной области и их свойств (атрибутов).


Один из популярных способов построения инфологической модели – построение ER-диаграмм.
ER-диаграммы
В отличие от диаграмм атрибутов, ER-диаграммы, кроме непосредственно атрибутов, включают так же в явном виде “сущности” и “связи” между ними, откуда, собственно, и происходит название: entity-relationship diagram, или диаграмма сущности-связи.
И сущности, и связи могут обладать набором атрибутов. Сущности без атрибутов – явление достаточно бессмысленное, как Кантовская “вещь в себе”. Связи без атрибутов – явление, напротив, весьмя распространенное.
Строго говоря, на диаграмме обозначаются классы сущностей. Во избежание путаницы, под словом “сущность” будем понимать набор атрибутов, а набор значений этих атрибутов будем называть экземпляром сущности.
В наиболее распространенной нотации, атрибуты обозначаются овалами, сущности – прямоугольниками, а связи – ромбами.
Сущности и связи соединяются между собой линиями. Существуют различные нотации, подразумевающие различную степень подробности описания. Мы будем использовать упрощенную схему, в которой для каждой линии надписывается, как раз сущность участвует в связи: 1 или много раз (М). В связи могут участвовать две или более сущностей. Хотя многозначные связи (связи, в которых участвуют более двух сущностей) – не слишком распространенное явление, иногда они бывают необходимы.
Для каждой сущности могут быть выделены один или несколько идентифицирующих атрибутов, так же, по аналогии с реляционной моделью, называемых ключом. Значения ключа сущности однозначно идентифицируют экземпляр сущности, так же как значение потенциального ключа отношения однозначно идентифицирует запись. Понятно, что ключей может быть несколько – по крайней мере один ключ, включающий все атрибуты сущности, должен существовать – назовем его тривиальным. Кроме того, возможно существуют ключи-подмножества тривиального. Условимся, что из всех ключей мы выбираем один минимальный, и используем его (назовем его первичным).
Атрибуты, входящие в первичный ключ на ER-диаграмме подчеркиваются.
Рассмотрим ER-диаграмму для примера с теннисными кортами.
Нормальная форма элементарного ключа (НФЭК)
НФЭК предложена Карло Занионо в 1982 году в качестве “компромисса” между 3НФ и НФБК.
- Элементарная ФЗ
- Функциональная зависимость \(f \in G\), \(f = X\to A\) называется элементарной, если она нетривиальна и замыкание \(G^+\) не содержит ФЗ \(X’\to A\) такого, что \(X’ \subset X\).
- Элементарный ключ
- Суперключ \(X\) отношения \(R\) называется элементарным ключом, если \(R\) удовлетворяет элементарной ФЗ \(X\to A\), где \(A\) – некий атрибут \(R\).
Отношение находится в НФЭК, если
- Оно находится в 3НФ
- Любая его элементарная ФЗ имеет в левой части суперключ или в правой части находится подмножество какого-либо элементарного ключа.
Иначе, отношение находится в НФЭК, если для любой его ФЗ \(X\to A\) выполняется хотя бы одно из условий:
- \(A\subset X\)
- \(X\) является суперключом.
- A входит в состав элементарного ключа
Декомпозиция без потерь
Как было сказано ранее, получить более высокую нормальную форму можно при помощи декомпозиции отношений.
- Декомпозиция
- Составление проекций \(S\), \(T\) исходного отношения \(R\), таких, что объединение заголовков \(S\) и \(T\) совпадает с заголовком \(R\).
Однако, не всякая декомпозиция допустима.
Выделяют два типа декомпозиции, используемой для нормализации.
- Декомпозиция без потерь
- Такая декомпозиция \(R\) в \((S,T)\), что \(R = S\bowtie T\).
Декомпозиция без потерь (lossless-join) позволяет восстановить исходное отношение при помощи операции соединения.
Как выбрать декомпозиции без потерь из всех возможных? Ответ на этот вопрос дает теорема Хита.
- Теорема Хита
- Пусть дано отношение \(R(A,B,C)\). Если \(R\) удовлетворяет функциональной зависимости \(A\to B\) , то \(R = \pi_{A,B} R \bowtie \pi_{A,C} R\).
Декомпозиция без потерь, однако, может не сохранять функциональные зависимости.
Например, пусть дано отношение \(R(A,B,C)\), удовлетворяющее ФЗ \(F_R=\{(A,B)\to C,C\to A\}\). По теореме Хита, \(C\to A \Rightarrow R=S(B,C)\bowtie T(C,A)\). Тогда ФЗ отношения \(S\) \(F_S=\{B\to B, C\to C\}^+\), и ФЗ отношения \(T\) \(F_T=\{C\to A\}^+\). Но \(((A,B)→C)\notin (F_S\cup F_T)^+\), и в результате оказывается потеряна.
Всегда существует декомпозиция без потерь до НФБК.
- Декомпозиция, сохраняющая зависимости
- Такая декомпозиция \(R\) в \((S,T)\), что замыкание множества ФЗ отношения \(R\) совпадает с замыканием объединения ФЗ отношений \(S\) и \(T\).
Декомпозиция, сохраняющая зависимости (dependency-preserving) сохраняет неизменным замыкание ФЗ всех отношений БД.
Всегда существует декомпозиция до НФЭК, сохраняющая зависимости. Однако, не всегда возможна декомпозиция, сохраняющая зависимости, до НФБК.
Перед началом…
Перед тем, как мы начнем изучать правила нормализации и применять их, мы должны разобраться со следующими понятиями.
Избыточность
Одним из основных моментов, который нужно учитывать при проектировании таблиц — уменьшение пространства для хранения данных. Таблицы должны быть спроектированы таким образом, чтобы повторяющиеся данные хранились отдельно, в одной или нескольких таблицах. Хранение повторяющихся данных не только требует больше места, но также приводит к более серьезным проблемам.
Таблица с данными о сотрудниках из разных отделов, содержит избыточные данные
Обратите внимание, что данные в полях DNAME и DNO неоднократно повторяются в таблице. Такой вид избыточности данных приводит к аномалиям обновления, вставки и удаления
Аномалии вставки
Если нам понадобится добавить в таблицу информацию о новом сотруднике, который не «привязан» к какому-либо отделу, данные об отделе в добавляемой записи окажутся пустыми, а это явно неоправданная трата пространства. Кроме того, при вставке данных нового сотрудника, скажем, в отдел с идентификатором ‘4’, другие поля, относящиеся к отделу, также должны будут повториться. Пример: отдел 4, поле DNAME должно содержать значение ‘Administrator’, а поле MGR_SSN — содержимое должно быть равно ‘234567890’.
Аномалии обновления
Если мы изменим значение какого-либо поля, относящегося к отделу, например, DNAME или MGR_SSN, мы должны будем изменить это значение у записей всех сотрудников, которые работают в этом отделе. Иначе, база данных будет находиться в несогласованном состоянии.
Аномалии удаления
Предположим, мы удалим информацию об одном сотруднике, например, последнюю запись из представленной выше таблицы. Только у этой записи значение в поле DNO равно ‘1’, в результате этого действия получится, что информация об отделе будет потеряна. Это нелепо, потому что мы хотим удалить информацию о сотруднике, а не обо всем отделе.
Функциональные зависимости
Функциональные зависимости — основа нормализации баз данных. Под функциональной зависимостью подразумевается зависимость значения одного поля (столбца) от другого. Например, по значению поля SSN определенного работника, мы сможем найти его адрес. Это значит, что поле адрес функционально зависимо от поля SSN. Символическая запись этой зависимости выглядит так:
{SSN} → {ADDRESS}
Аналогично,
{SSN} → {ENAME, ADDRESS} {SSN, DNO} → {MGR_SSN}
Когда значение одного или нескольких полей точно идентифицируют запись, значение такого поля называется «первичным ключом».
Плюсы
Нормализация не является обязательной, но приносит следующие преимущества:
— упрощается процесс выборки. Речь идет об упрощении работы по составлению запросов, то есть пользователь сможет получать нужную информацию относительно простыми запросами;
— обеспечивается целостность данных. Можно говорить о минимизации искажения информации и снижении вероятности потери данных;
— улучшается масштабируемость. При соблюдении правил нормализации формируются благоприятные предпосылки к росту БД;
— отсутствует избыточность (data redundancy). Избыточность — известная проблема непродуктивного использования свободного места на жестком диске, затрудняющая обслуживание БД. В отдельных случаях эту проблему усугубляет и то, что в случае необходимости изменения записей однотипных данных, хранимых в нескольких местах (таблицах), пользователю придется вносить требуемые изменения везде, что весьма трудоемкое занятие. Гораздо проще сделать так, чтобы, к примеру, данные о городах хранились только в таблице Cities и нигде больше. Если подытожить вышесказанное, избыточность предполагает дублирование данных, а это не только усложняет работу с БД, но и увеличивает ее размер;
— отсутствие несогласованных зависимостей. Несогласованные зависимости затрудняют доступ к данным, ведь путь к такой информации может быть неправилен и нелогичен. В той же таблице Cities логично искать города, количество жителей и т. п., но не адреса и имена жителей — для этой информации уже нужна другая таблица — Citizens.