
Вместо послеловия
В общем и целом, это вкратце и все, что касается рассмотрения вопроса, что такое мощность алфавита. Остается добавить, что в данном описании был использован чисто математический подход. Само собой разумеется, что смысловая нагрузка текста в данном случае не учитывается.
Но, если подходить к вопросам рассмотрения именно с позиции, которая дает человеку что-то для осмысления, набор бессмысленного сочетания или последовательностей символов в этом плане будет иметь нулевую информационную нагрузку, хотя, с точки зрения понятия информационного объема, результат все равно можно вычислить.
В целом же, знания о мощности алфавита и сопутствующих понятиях не так уж и сложны для понимания и элементарно могут применяться в смысле практических действий. При этом любой пользователь практически каждый день сталкивается с этим. Достаточно привести в пример популярный редактор Word или любой другой такого же уровня, в котором используется такая система. Но не путайте его с обычным «Блокнотом». Здесь мощность алфавита ниже, поскольку при наборе текста не используются, скажем, прописные буквы.
Как устроена кодировка UTF-8
В UTF-8 каждый символ кодируется разным количеством байтов — всё зависит от того, какой длины исходное число. Сначала расскажем теорию, потом нарисуем, как это работает.
До 7 бит — выделяется один байт, первый бит всегда ноль: 0xxxxxxxx. Иксы — это биты нашего числа. Например, буква A стоит на 65-м месте в таблице, а если перевести 65 в двоичный код, получится 1000001. Ставим эти 7 бит в наш шаблон и получаем нужный юникод-байт: 01000001.
Ноль здесь — признак того, что перед нами символ из первых 128 символов таблицы. Они совпадают с таблицей ASCII, поэтому одним байтом можно закодировать все стандартные математические символы, знаки препинания и буквы латинского алфавита.
Если первым в символе идёт ноль, кодировка понимает, что перед нами — один восьмибитный символ. Двух-, трёх- и четырёхбайтные символы всегда начинаются с единицы.
8—11 бит: выделяется два байта — 110xxxxx 10xxxxxx. Две единицы в начале говорят, что перед нами символ из двух байтов. Последовательность 10 в начале второго байта — признак того, что это продолжение предыдущего байта.
12—16 бит: тут уже три байта — 1110xxxx 10xxxxxx 10xxxxxx. Три единицы в начале — признак трёхбайтного символа. Каждый байт продолжения начинается с 10.
17—21 бит: для кодирования нужно четыре байта: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx.
Короче: в кодировке UTF договорились, что много байтов выделяют только на те символы, которые стоят где-то в глубине таблицы, то есть всякие сложные национальные кодировки, эмодзи и иконки. Чем ближе к началу таблицы символ, тем меньше байтов на него выделяют. А чтобы компьютер понимал, сколько байтов выделено на каждый конкретный символ, сначала ставят специальные маркеры-подсказки.
В-четвертых, проблема Unicode
Следует отметить, что Unicode — это просто набор символов, он только указывает двоичный код символа, но не указывает, как этот двоичный код должен храниться.
Например, китайские иероглифыЮникод — это шестнадцатеричное число., Преобразуется в двоичное число с 15 битами (), то есть для представления этого символа требуется не менее 2 байтов. Представляет другие символы большего размера, для которых может потребоваться 3 или 4 байта или даже больше.
Здесь возникают два серьезных вопроса. Первый вопрос: как отличить Unicode от ASCII? Как компьютер узнает, что три байта представляют собой символ, а не три символа по отдельности? Вторая проблема заключается в том, что мы уже знаем, что английские буквы представлены только одним байтом.Если Unicode предусматривает, что каждый символ представлен тремя или четырьмя байтами, то перед каждой английской буквой должно стоять два. До трех байтов, Это огромная трата памяти, размер текстового файла будет в два-три раза больше, что недопустимо.
Результатом этого является: 1) Существует несколько методов хранения Unicode, что означает, что существует множество различных двоичных форматов, которые могут использоваться для представления Unicode. 2) Юникод нельзя продвигать долго, до появления Интернета.
Определение информационного объёма в тексте
Почти всегда при наборе текста на компьютерах и других электронных устройствах приходится сталкиваться с написанием различных символов. К ним следует отнести:
- заглавные и жирные буквы;
- курсив;
- скобки;
- знаки препинания;
- вычислительные операции и прочее.

Размер любой напечатанной фразы может быть вычислен по формуле V=K ⋅ log2N. В этом случае N обозначает количество всех символов в алфавите, а K — это численность знаков непосредственно в напечатанной фразе. Так, например, имеется произвольный текст объёмом в 25 листов. На каждом из них расположено по 45 строчек текста, содержащих по 58 символов.
Исходя из этого, на любой отдельной странице будет 45*58 = 2610 байт информации. В целом же по всему тексту этот объём будет равен 2610*25 = 65250 байт. Для обозначения мощности алфавита в информатике общепринятым вариантом является буква N из формулы Хартли. Именно ее чаще всего указывают в большинстве учебников и профессиональной литературе.
В кодовой таблице ASCII используют восьмибитную кодировку текстовых сообщений. Она позволяет полностью вместить основной набор символов кириллического и латинского алфавитов как в строчном, так и в прописном вариантах. Также с её помощью можно отобразить знаки препинания, цифры и прочие базовые знаки. Часто пользователям приходится иметь дело с более крупными объёмами, состоящими из триллионов байтов.
Поскольку один отдельный символ состоит из 8 битов, то устанавливать их кодировку целиком не представляется возможным. Вместо этого предпочтительнее образовать кодировку трёхбитовых комбинаций. Расчёт этого действия проводится по формуле Хартли, где n-ная степень будет равняться трём. В результате получается N, равная 8.
При определении мощности чаще всего используют алфавитный подход. Он говорит о том, что объём информации, заложенной в тексте, зависит исключительно от мощности самого алфавита и размера сообщения (то есть количества символов, содержащихся в нём). Этот показатель не имеет никакой связи со смысловым наполнением для человека.
Юникод: необходимый практический минимум для каждого разработчика +43
- 13.10.16 18:31
•
kdenisk
•
#312642
•
Хабрахабр
•
•
16400
Программирование
Рекомендация: подборка платных и бесплатных курсов создания сайтов — https://katalog-kursov.ru/
Юникод — это очень большой и сложный мир, ведь стандарт позволяет ни много ни мало представлять и работать в компьютере со всеми основными письменностями мира. Некоторые системы письма существуют уже более тысячи лет, причём многие из них развивались почти независимо друг от друга в разных уголках мира. Люди так много всего придумали и оно зачастую настолько непохоже друг на друга, что объединить всё это в единый стандарт было крайне непростой и амбициозной задачей.
Чтобы по-настоящему разобраться с Юникодом нужно хотя бы поверхностно представлять себе особенности всех письменностей, с которыми позволяет работать стандарт. Но так ли это нужно каждому разработчику? Мы скажем, что нет. Для использования Юникода в большинстве повседневных задач, достаточно владеть разумным минимумом сведений, а дальше углубляться в стандарт по мере необходимости.
В статье мы расскажем об основных принципах Юникода и осветим те важные практические вопросы, с которыми разработчики непременно столкнутся в своей повседневной работе.
Зачем понадобился Юникод?
- Можно было одновременно работать лишь с 256 символами, причём первые 128 были зарезервированы под латинские и управляющие символы, а во второй половине кроме символов национального алфавита нужно было найти место для символов псевдографики (г ¬).
- Шрифты были привязаны к конкретной кодировке.
- Каждая кодировка представляла свой набор символов и конвертация из одной в другую была возможна только с частичными потерями, когда отсутствующие символы заменялись на графически похожие.
- Перенос файлов между устройствами под управлением разных операционных систем был затруднителен. Нужно было либо иметь программу-конвертер, либо таскать вместе с файлом дополнительные шрифты. Существование Интернета каким мы его знаем было невозможным.
- В мире существуют неалфавитные системы письма (иероглифическая письменность), которые в однобайтной кодировке непредставимы в принципе.
Важно!
еe
В сухом остатке
- Юникод постулирует чёткое разграничение между символами, их представлением в компьютере и их отображением на устройстве вывода.
- Юникод-символы не всегда соответствуют символу в традиционно-наивном понимании, например букве, цифре, пунктуационному знаку или иероглифу.
- Кодовое пространство Юникода состоит из 1 114 112 кодовых позиций в диапазоне от 0 до 10FFFF.
- Базовая многоязыковая плоскость включает в себя юникод-символы от U+0000 до U+FFFF, которые кодируются в UTF-16 двумя байтами.
- Любая юникод-кодировка позволяет закодировать всё пространство кодовых позиций Юникода и конвертация между различными такими кодировками осуществляется без потерь информации.
- Однобайтные кодировки позволяют закодировать лишь небольшую часть юникод-спектра, но могут оказаться полезными при работе с большим объёмом моноязыковой информации.
- Кодировки UTF-8 и UTF-16 обладают переменной длиной кода. В UTF-8 каждый юникод-символ может быть закодирован одним, двумя, тремя или четырьмя байтами. В UTF-16 — двумя или четырьмя байтами.
- Внутренний формат хранения текстовой информации в рамках отдельного приложения может быть произвольным при условии корректной работы со всем пространством кодовых позиций Юникода и отсутствии потерь при трансграничной передаче данных.
Измерение информационного объема
Однако это были всего лишь простейшие примеры, так сказать, для начального понимания того, что такое мощность алфавита. Перейдем непосредственно к практике.
На данном этапе развития компьютерной техники для набора текста с учетом заглавных, прописных и строчных букв, кириллических и латинских литер, знаков препинания, скобок, знаков арифметических действий и т.д. используется 256 символов. Исходя из того, что 256 это 2 8 , нетрудно догадаться, что вес каждого символа в таком алфавите равен 8, то есть, 8 битам или 1 байту.
Если исходить из всех известных параметров, можно с легкостью получить нужное нам значение информационного объема любого текста. Например, у нас есть компьютерный текст, содержащий 30 страниц. На одной странице располагается 50 строк по 60 любых знаков или символов, включая и пробелы.
Таким образом, одна страница будет содержать 50 х 60= 3 000 байт информации, а весь текст – 3000 х 50=150000 байт. Как видим даже небольшие тексты измерять в байтах неудобно. А что говорить о целых библиотеках?
В данном случае лучше переводить объем в более мощные величины – килобайты, мегабайты, гигабайты и т.д. Исходя из того, что, например, 1 килобайт равен 1024 байта (2 10 ), а мегабайт – 2 10 килобайт (1024 килобайта), нетрудно посчитать, что объем текста в информационно-математическом выражении для нашего примера составит 150000/1024=146,484375 килобайт или приблизительно 0,14305 мегабайт.
Линейный поиск
Начнём с самого простого алгоритма — линейного поиска, он же linear search. Дальнейшее объяснение подразумевает, что вы знаете, что такое числа и как устроены массивы. Напомню, это всего лишь набор проиндексированных ячеек.
Допустим, у нас есть массив целых чисел arr, содержащий n элементов. Вообще, количество элементов, размер строк, массивов, списков и графов в алгоритмах всегда обозначают буквой n или N. Ещё дано целое число x. Для удобства обусловимся, что arr точно содержит x.
Задача: найти, на каком месте в массиве arr находится элемент 3, и вернуть его индекс.
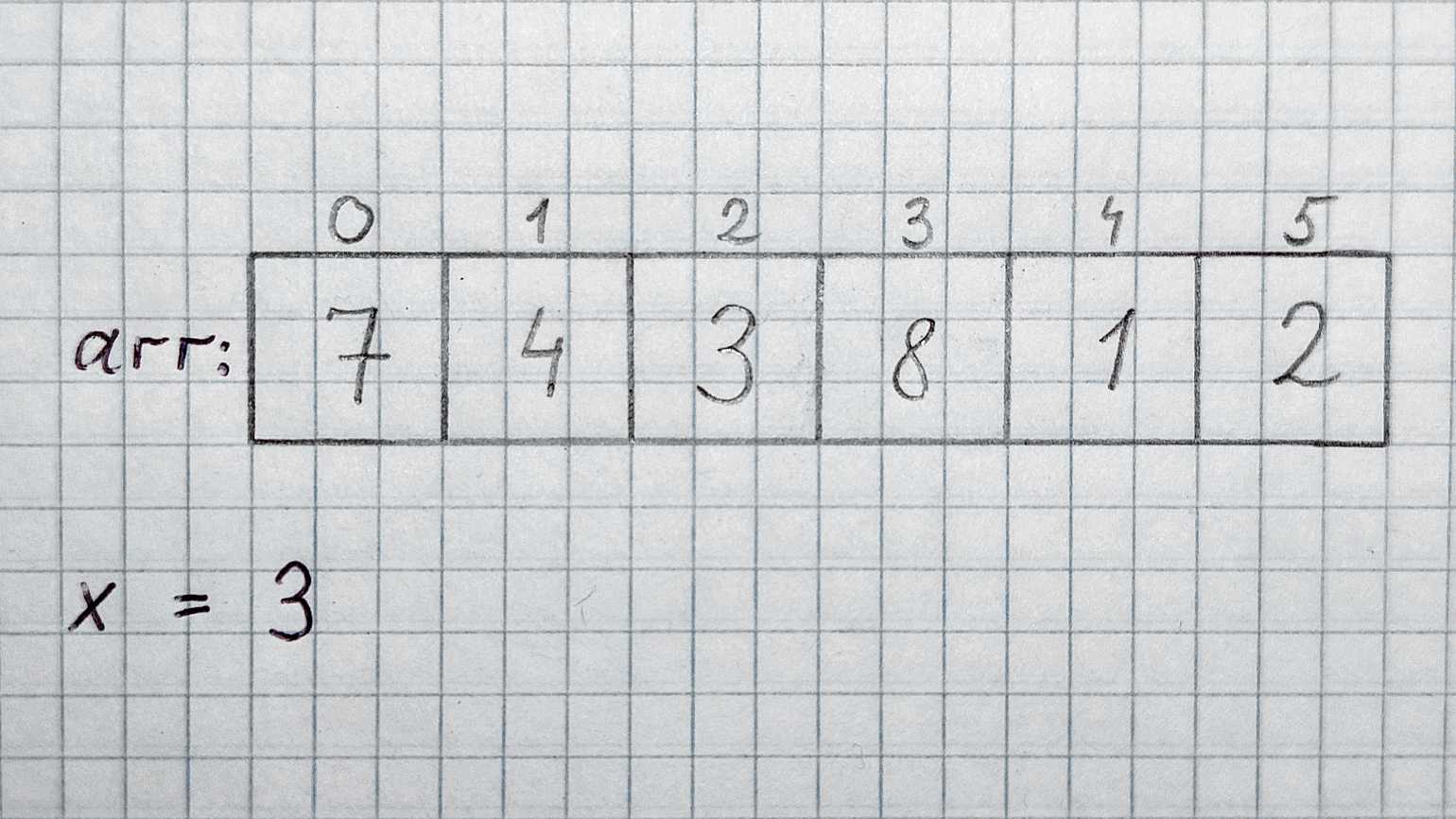
Фото: Валерий Жила для Skillbox Media
Меткий человеческий глаз сразу видит, что искомый элемент содержится в ячейке с индексом 2, то есть в arr. А менее зоркий компьютер будет перебирать ячейки друг за другом: arr, arr… и так далее, пока не встретит тройку или конец массива, если тройки в нём нет.
Теперь разберём случаи:
Worst case. Больше всего шагов потребуется, если искомое число стоит в конце массива. В этом случае придётся перебрать все n ячеек, прочитать их содержимое и сравнить с искомым числом. Получается, worst case равен O(n). В нашем массиве худшему случаю соответствует x = 2.








Best case. Если бы искомое число стояло в самом начале массива, то мы бы получили ответ уже в первой ячейке. Best case линейного поиска — O(1). Именно так обозначается константное время в Big O Notation. В нашем массиве best case наблюдается при x = 7.
3 вариант
1. В одной из кодировок Unicode каждый символ кодируется 16 битами. Игорь Иванович написал текст (в нём нет лишних пробелов):
Кислород, углерод, водород, азот, фосфор, калий, сера, хлор, кальций, магний, натрий, железо, цинк, медь, йод — важные химические элементы.
Потом он удалил из списка несколько 6-буквенных названий химических элементов. Заодно он удалил ставшие лишними запятые и пробелы — два пробела не должны идти подряд. При этом размер нового предложения в данной кодировке оказался на 48 байт меньше, чем размер исходного предложения. Сколько 6-буквенных названий было удалено Игорем Ивановичем? В ответе укажите одно число.
2. В одной из кодировок Unicode каждый символ кодируется 2 байтами. Кристина написала текст (в нём нет лишних пробелов):
Газ, уран, золото, серебро, фосфатные руды, известняк, медная руда, уголь, марганец, никель, платина, торф, глина, мел, магнетит, древесина — названия полезных ископаемых.
Ученица удалила из списка название одного полезного ископаемого. Заодно она удалила ставшие лишними запятые и пробелы — два пробела не должны идти подряд. При этом размер нового предложения в данной кодировке оказался на 112 бит меньше, чем размер исходного предложения. Среди названий с одинаковым количеством букв, Кристина удалила последнее по порядку следования. Запишите в ответе название полезного ископаемого, которое удалила Кристина.
3. В кодировке UTF-32 каждый символ кодируется 4 байтами. Георгий написал текст (в нём нет лишних пробелов):
Газ, уран, золото, серебро, фосфатные руды, известняк, медная руда, уголь, марганец, никель, платина, торф, глина, мел, магнетит, древесина — названия полезных ископаемых.
Ученик удалил из списка название одного полезного ископаемого. Заодно он удалил ставшие лишними запятые и пробелы — два пробела не должны идти подряд. При этом размер нового предложения в данной кодировке оказался на 256 бит меньше, чем размер исходного предложения. Среди названий, имеющих одинаковое количество букв, Георгий удалил первое в порядке следования. Запишите в ответе название полезного ископаемого, удаленное Георгием.
4. В кодировке КОИ-8 каждый символ кодируется 1 байтом. Матвей написал текст (в нём нет лишних пробелов):
Лев, Дева, Весы, Скорпион, Стрелец, Козерог, Водолей, Рыбы, Телец, Близнецы, Рак — названия знаков зодиака.
Ученик удалил из списка название одного знака зодиака. Заодно он удалил ставшие лишними запятые и пробелы — два пробела не должны идти подряд. При этом размер нового предложения в данной кодировке оказался на 72 бита меньше, чем размер исходного предложения. Среди знаков зодиака, имеющих одинаковое количество букв, Матвей удалил название, идущее последним по алфавиту. Запишите в ответе название знака зодиака, удаленное Матвеем.
5. В одной из кодировок UTF-32 каждый символ кодируется 4 байтами. Ольга написала текст (в нём нет лишних пробелов):
Лев, Дева, Весы, Скорпион, Стрелец, Козерог, Водолей, Рыбы, Телец, Близнецы, Рак — знаки зодиака.
Ученица вычеркнула из списка все четырехбуквенные названия знаков зодиака. Заодно она вычеркнула ставшие лишними запятые и пробелы — два пробела не должны идти подряд. На сколько байт уменьшился размер отредактированного текста?
В ответе запишите число.
Ответы на тест по информатике Оценка объема памяти, необходимой для хранения текстовых данных 9 класс1 вариант
1. УГАНДА
2. КОЗЕРОГ
3. ТАНЗАНИЯ
4. АНДРОМЕДА
5. БРЮССЕЛЬ2 вариант
1. 2
2. ВАДИМ
3. 130
4. ФОСФОР
5. РЕЙКЬЯВИК3 вариант
1. 3
2. ГЛИНА
3. ЗОЛОТО
4. СТРЕЛЕЦ
5. 72
Ответы на тест 1 по Информатике 8 класс
«Ответы на тест 1 по Информатике 8 класс» — это пособие для родителей для проверки правильности ответов обучающихся детей (ГДЗ) на «Тестовые вопросы для самоконтроля», указанные в учебнике Информатики в конце 1-й главы. Как утверждают авторы учебника (Л.Л.Босова, А.Ю.Босова) в конце каждой главы приведены тестовые задания, которые помогут оценить, хорошо ли учащиеся освоили теоретический материал и могут ли они применять свои знания для решения возникающих проблем.
Ответы на вопросы помогут родителям оперативно проверить выполнение указанных заданий.
а) системой счисления
б) цифрами системы счисления
в) алфавитом системы счисления
г) основанием системы счисления
Правильный ответ: в) алфавитом системы счисления
-
Чему равен результат сложения двух чисел, записанных римскими цифрами: МСМ + LXVIII?
а) 1168
б) 1968
в) 2168
г) 1153
Правильный ответ: б) 1968
а) 2 и 10
б) 4 и 3
в) 4 и 8
г) 2 и 4
Правильный ответ: в) 4 и 8
а) 36
б) 38
в) 37
г) 46
Правильный ответ: б) 38
а) 10
б) 20
в) 30
г) 40
Правильный ответ: б) 20
а) 1
б) 2
в) 3
г) 4
а) 610
б) 1010
в) 100002
г) 178
Правильный ответ: в) 100002
а) кодами
б) разрядами
в) цифрами
г) коэффициентами
Правильный ответ: б) разрядами
а) 8
б) 16
в) 32
г) 64
Правильный ответ: б) 16
а) +
б) —
в) 0
г) 1
а) естественной форме
б) развёрнутой форме
в) экспоненциальной форме с нормализованной мантиссой
г) виде обыкновенной дроби
Правильный ответ: в) экспоненциальной форме с нормализованной мантиссой
а) Никакая причина не извиняет невежливость.
б) Обязательно стань отличником.
в) Рукописи не горят.
г) 10112 = 1 • 23 + 0 • 22 + 1 • 21 + 1 • 2
Правильный ответ: б) Обязательно стань отличником
а) Знаком v обозначается логическая операция ИЛИ.
б) Логическую операцию ИЛИ также называют логическим сложением.
в) Дизъюнкцию также называют логическим сложением.
г) Знаком v обозначается логическая операция конъюнкция.
а) 1
б) 2
в) 3
г) 4
Правильный ответ: а) 1
а) abcde
б) bcade
в) babas
г) cabab
Правильный ответ: а) abcde
| Ключевое слово | Количество сайтов, для которых данное слово является ключевым |
| Сканер | 200 |
| Принтер | 250 |
| Монитор | 450 |
Сколько сайтов будет найдено по запросу принтер | сканер \ монитор, если по запросу принтер \ сканер было найдено 450 сайтов, по запросу принтер & монитор — 40, а по запросу сканер & монитор — 50?
а) 900
б) 540
в) 460
г) 810
| A | B | F |
| 1 | ||
| 1 | 1 | |
| 1 | 1 | |
| 1 | 1 |
Правильный ответ: в)
а) оперативная память
б) процессор
в) жёсткий диск
г) процессор и оперативная память
Правильный ответ: б) процессор
а) АМЛГ
б) АГЛМ
в) ГЛМА
г) МЛГА
Правильный ответ: б) АГЛМ
Два, не-ASCII кодирование
Кодировки на английском языке 128 символов достаточно, но для других языков 128 символов недостаточно. Например, во французском языке, если над буквой есть фонетический символ, он не может быть представлен кодом ASCII. В результате некоторые европейские страны решили использовать старший бит неиспользуемого байта для программирования нового символа. Например, на французскомКод 130 (двоичный). Таким образом, система кодирования, используемая в этих европейских странах, может представлять до 256 символов.
Однако здесь возникли новые проблемы. В разных странах используются разные буквы, поэтому даже если все они используют методы кодирования 256 символов, они представляют разные буквы. Например, 130 во французском коде означает, Который представляет буквы в кодировке иврита (), который будет представлять другой символ в русской кодировке. Но в любом случае, во всех этих методах кодирования символы, представленные цифрами 0–127, одинаковы, и единственное отличие — это сегмент 128–255.
Что касается шрифтов азиатских стран, то здесь используется больше символов, насчитывающих до 100 000 китайских иероглифов. Один байт может представлять только 256 видов символов, что явно недостаточно, и для представления одного символа необходимо использовать несколько байтов. Например, распространенным методом кодирования для упрощенного китайского языка является GB2312, который использует два байта для представления китайского символа, поэтому теоретически он может представлять до 256 x 256 = 65536 символов.
Вопрос о китайской кодировке необходимо обсудить в специальной статье, которая не освещена в этой заметке. Здесь только указано, что, хотя для представления символа используется несколько байтов, китайская кодировка символов типа GB не имеет ничего общего с Unicode и UTF-8 ниже.
Понимание Схем Кодирования
Кодировка символов может принимать различные формы в зависимости от количества символов, которые она кодирует.
Количество закодированных символов имеет прямое отношение к длине каждого представления, которое обычно измеряется как количество байтов. Наличие большего количества символов для кодирования по существу означает необходимость более длинных двоичных представлений.






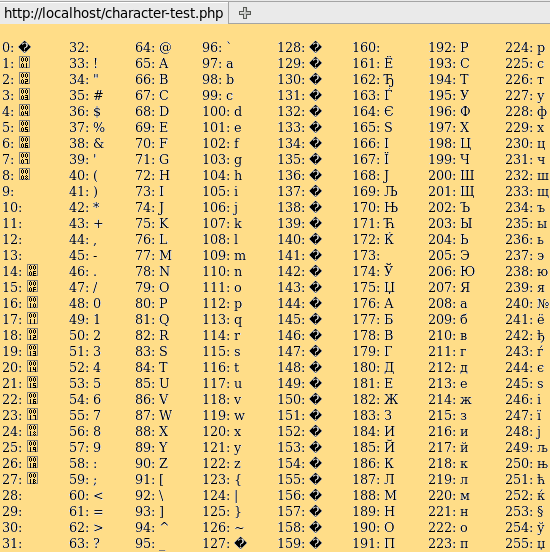
Давайте рассмотрим некоторые из популярных схем кодирования на практике сегодня.
4.1. Однобайтовое кодирование
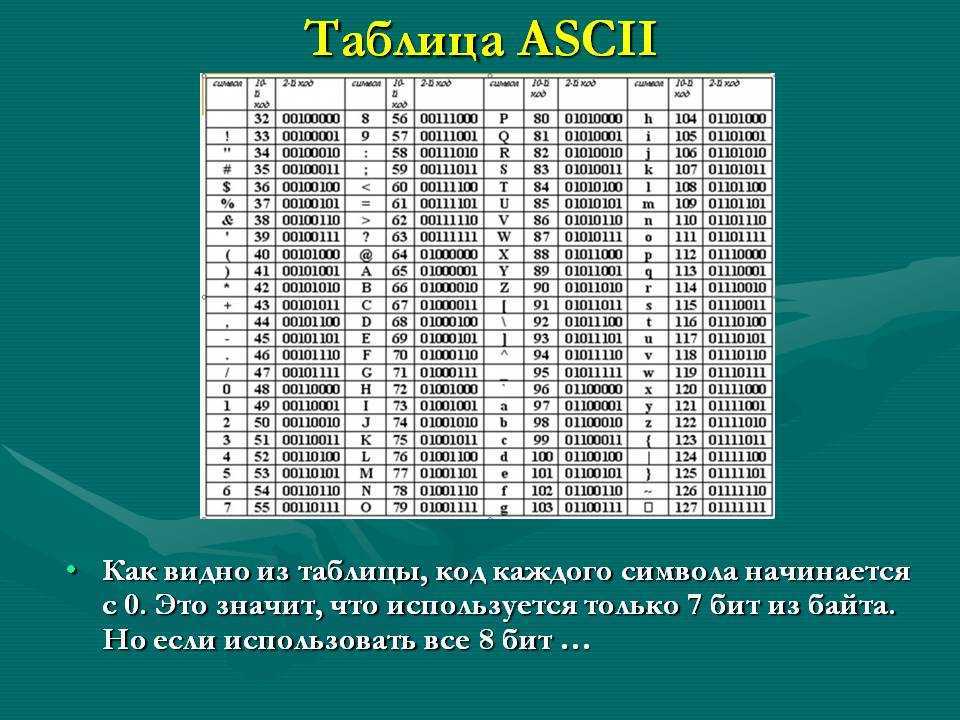
Одна из самых ранних схем кодирования, называемая ASCII (Американский стандартный код для обмена информацией), использует однобайтовую схему кодирования. По сути, это означает, что каждый символ в ASCII представлен семибитными двоичными числами. Это все еще оставляет один бит свободным в каждом байте!
Ascii 128-символьный набор охватывает английские алфавиты в нижнем и верхнем регистрах, цифры и некоторые специальные и контрольные символы.
Давайте определим простой метод в Java для отображения двоичного представления символа в определенной схеме кодирования:
String convertToBinary(String input, String encoding)
throws UnsupportedEncodingException {
byte[] encoded_input = Charset.forName(encoding)
.encode(input)
.array();
return IntStream.range(0, encoded_input.length)
.map(i -> encoded_input)
.mapToObj(e -> Integer.toBinaryString(e ^ 255))
.map(e -> String.format("%1$" + Byte.SIZE + "s", e).replace(" ", "0"))
.collect(Collectors.joining(" "));
}
Теперь символ ” T ” имеет кодовую точку 84 в US-ASCII (ASCII в Java называется US-ASCII).
И если мы используем наш метод утилиты, мы можем увидеть его двоичное представление:
assertEquals(convertToBinary("T", "US-ASCII"), "01010100");
Это, как мы и ожидали, семиразрядное двоичное представление символа “T”.
Исходный ASCII оставил самый значимый бит каждого байта неиспользованным. В то же время ASCII оставил довольно много непредставленных символов,
Исходный ASCII оставил самый значимый бит каждого байта неиспользованным. || В то же время ASCII оставил довольно много непредставленных символов,
Было предложено и принято несколько вариантов схемы кодирования ASCII.
Многие расширения ASCII имели разные уровни успеха, но, очевидно, это
Одним из наиболее популярных расширений ASCII был ISO-8859-1 , также называемый “ISO Latin 1”.
4.2. Многобайтовое кодирование
Поскольку потребность в размещении все большего количества символов росла, однобайтовые схемы кодирования, такие как ASCII, не были устойчивыми.
Это привело к появлению многобайтовых схем кодирования, которые имеют гораздо большую емкость, хотя и за счет увеличения требований к пространству.
BIG 5 и SHIFT-JIS являются примерами многобайтовых схем кодирования символов, которые начали использовать как один, так и два байта для представления более широких наборов символов . Большинство из них были созданы для того, чтобы представлять китайские и аналогичные сценарии, которые имеют значительно большее количество символов.
Давайте теперь вызовем метод convertToBinary с вводом как “語”, китайский символ, и кодирование как “Big5”:
assertEquals(convertToBinary("語", "Big5"), "10111011 01111001");
Вывод выше показывает, что кодировка Big5 использует два байта для представления символа “語”.
полный список кодировок символов, наряду с их псевдонимами, ведется Международным органом по номерам.