
Все еще не можете открыть файл?
Если вы не можете заставить программы, указанные выше, открыть ваш файл, вы можете проверить расширение файла, чтобы убедиться, что он читает .BIB или .BIBTEX. Если расширение файла является чем-то еще, скорее всего, вы не можете использовать программы на этой странице, чтобы открыть файл.
Может быть легко перепутать любое расширение файла с другим форматом файла. Например, хотя BIB очень похож на BIN, они не связаны даже в малейшей степени и поэтому не могут открываться с помощью одних и тех же программ.
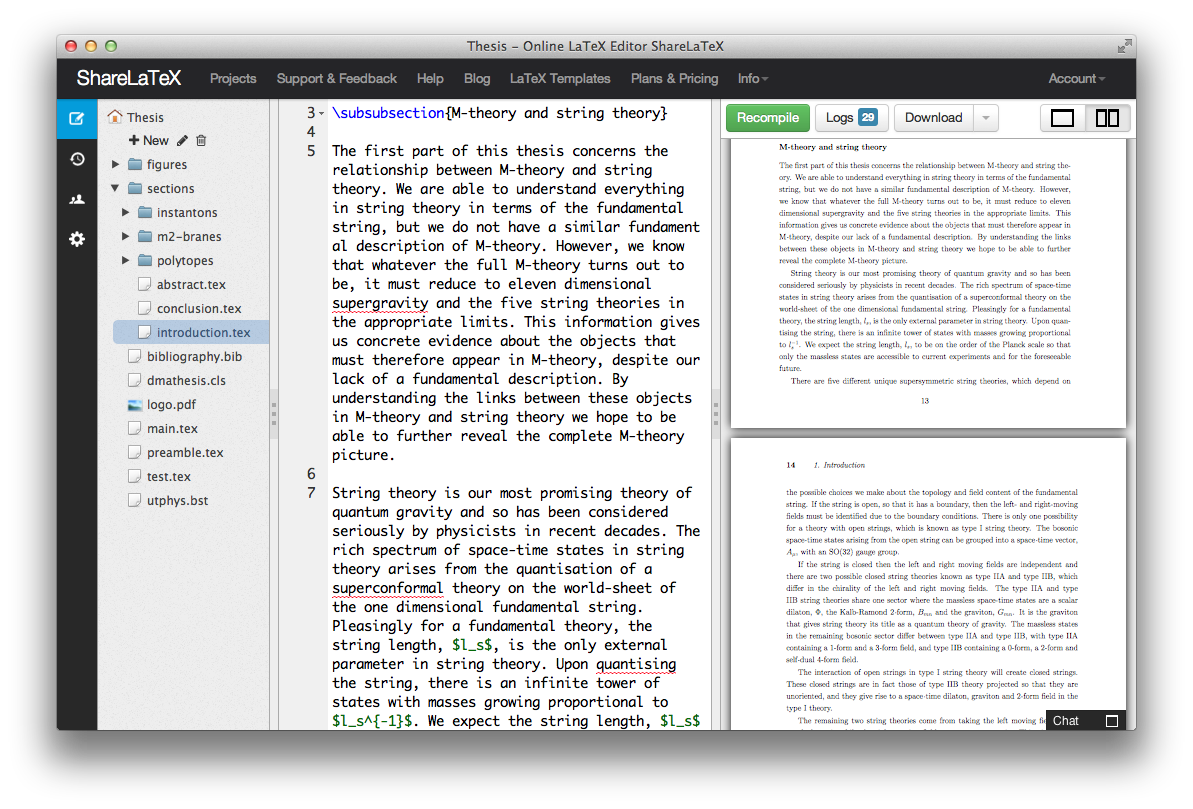
То же самое верно для файлов BIK, BIG, BIP и BIF. Идея состоит в том, чтобы убедиться, что расширение файла действительно говорит о том, что это файл BibTeX, в противном случае вам нужно изучить фактическое расширение файла, которое имеет ваш файл, чтобы узнать, как открыть или преобразовать файл.
-
Защита дисплея corning gorilla glass 3 что это
-
Как создать comtrade файл
-
Не работает микрофон в teamspeak
-
Проблема загрузки файла run exe
- Utorrent не сохраняет файлы в указанную папку android
Тип файла 1Библиографический документ
| разработчик | N / A |
| популярность | 3,6 (25 голосов) |
| категория | Текстовые файлы |
| Формат | N / A X
Категории форматов файлов включают в себя двоичные, текстовые, XML и Zip.Формат этого типа файла не был определен. |
| Windows |
|
| макинтош |
|
Тип файла 2BibTeX База данных библиографии
| разработчик | N / A |
| популярность | 3,4 (27 голосов) |
| категория | Текстовые файлы |
| Формат | Текст X
Этот файл сохраняется в текстовом формате. Вы можете открыть и просмотреть содержимое этого файла с помощью текстового редактора. |
Ассоциация файлов .BIB 2
Файл BIB представляет собой текстовый документ, созданный программой LaTeX, такой как MiKTeX или TeXworks. Он содержит список ссылок, отформатированных с использованием форматирования BibTeX. Файлы BIB позволяют осуществлять поиск и публикацию библиографий с использованием стандартных команд и часто используются в сочетании с документами LaTeX (.TEX). Дополнительная информация
.BIB Расширение файла image / bib_246.jpg «>
BIB файл открывается в TeXworks 0.6
Файлы BibTeX могут содержать библиографии для книг, статей, исследовательских работ, технических отчетов и т. Д. Пример записи в файле BIB может быть отформатирован следующим образом:
@BOOK {ключ цитирования, Файлы BibTeX можно просматривать и управлять ими на нескольких компьютерных системах, но форматирование является стандартным для всех платформ.
| Windows |
|
| макинтош |
|
| Linux |
|
О файлах BIB
Наша цель — помочь вам понять, что такое файл с суффиксом * .bib и как его открыть.
Все типы файлов, описания форматов файлов и программы, перечисленные на этой странице, были индивидуально исследованы и проверены командой FileInfo. Мы стремимся к 100% точности и публикуем информацию только о тех форматах файлов, которые мы тестировали и проверяли.
Если вы хотите предложить какие-либо дополнения или обновления на этой странице, пожалуйста, сообщите нам об этом.
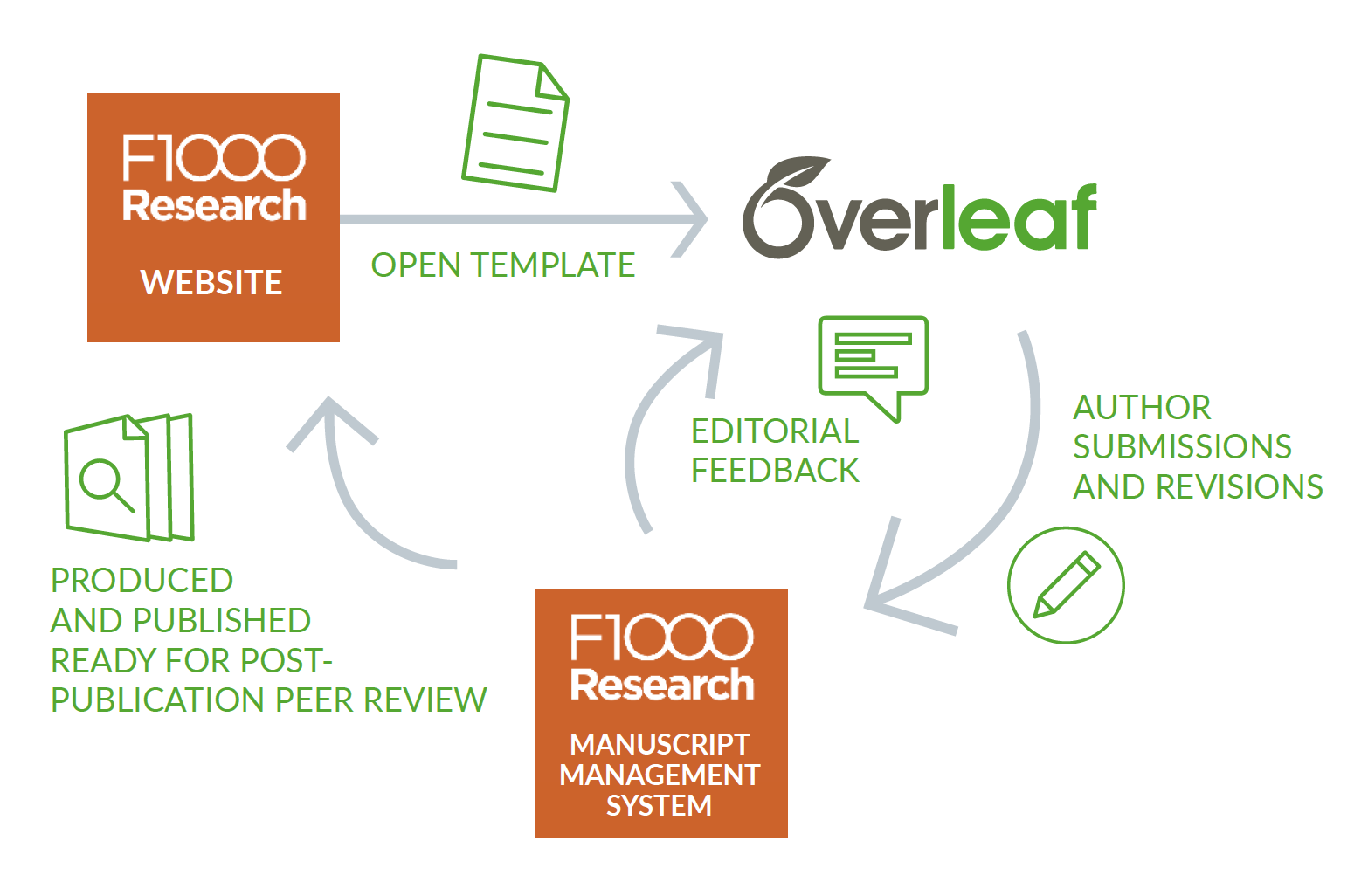
Autogenerate footnotes in \(\LaTeX\) using BibLaTeX
The abilities of BibTeX are limited to basic styles as depicted in the examples shown above. Sometimes it is necessary to cite all literature in footnotes and maintaining all of them by hand can be a frustrating task. At this point BibLaTeX kicks in and does the work for us. The syntax varies a bit from the first document. We now have to include the biblatex package and use the \autocite and \printbibliography command. It is crucial to move the \bibliography{lesson7a1} statement to the preamble of our document:
\documentclass{article}
\usepackage{biblatex}
\bibliography{lesson7a1}
\begin{document}
Random citation \autocite{DUMMY:1} embeddeed in text.
\newpage
\printbibliography
\end{document}
The \autocite command generates the footnotes and we can enter a page number in the brackets \autocite{DUMMY:1} will generate a footnote like this:
![]()
For BibLaTeX we have to choose the citation style on package inclusion with:
\usepackage{biblatex}
The backend=bibtex part makes sure to use BibTeX instead of Biber as our backend, since Biber fails to work in some editors like TeXworks. It took me a while to figure out how to generate footnotes automatically, because the sources I found on the internet, didn’t mention this at all.
How/where do I actually get those .bib files?
Edit the file as plain text
Because files are plain text you can certainly write them by hand—once you’re familiar with \(\mathrm{Bib\TeX}\)’s required syntax. Just make sure that you save it with a extension, and that your editor doesn’t surreptitiously add a or some other suffix. On Overleaf you can click on the “Files…” link at the top of the file list panel, and then on “Add blank file” to create a fresh file to work on.
Help from GUI-based editors
Export from reference library services
If you click on the Upload files button above the file list panel, you’ll notice some options: Import from Mendeley, and Import from Zotero. If you’re already using one of those reference library management services, Overleaf can now hook into the Web exporter APIs provided by those services to import the file (generated from your library) into your Overleaf project. For more information, see the Overleaf article How to link your Overleaf account to Mendeley and Zotero.
Источники проблем с BIBTEX
Общие проблемы с открытием файлов BIBTEX
MacroMates TextMate нет
При попытке открыть BIBTEX-файл возникает сообщение об ошибке, например «%%os%% не удается открыть BIBTEX-файлы». Обычно это связано с тем, что у вас нет MacroMates TextMate для %%os%% установлен. Типичный путь открытия документа BIBTEX двойным щелчком не будет работать, так как %%os%% не может установить подключение к программе.
Совет: Другая программа, связанная с BIBTEX, может быть выбрана, чтобы открыть файл, нажав «Показать приложения» и найдя приложение.
MacroMates TextMate требует обновления
В некоторых случаях может быть более новая (или более старая) версия файла BibTeX Bibliography Database, которая не поддерживается установленной версией приложения. Рекомендуется установить последнюю версию MacroMates TextMate из MacroMates. Большую часть времени файл BibTeX Bibliography Database был создан более новым MacroMates TextMate, чем то, что вы установили.
Совет: Иногда вы можете получить подсказку о версии BIBTEX-файла, который у вас есть, щелкнув правой кнопкой мыши на файле, а затем нажав на «Свойства» (Windows) или «Получить информацию» (Mac OSX).
Резюме: В любом случае, большинство проблем, возникающих во время открытия файлов BIBTEX, связаны с отсутствием на вашем компьютере установленного правильного прикладного программного средства.
В большинстве случаев установка правильной версии MacroMates TextMate решит вашу проблему. Другие ошибки открытия BIBTEX могут быть созданы другими системными проблемами внутри %%os%%. Проблемы, не связанные с программным обеспечением:
How/where do I actually get those .bib files?
Edit the file as plain text
Because files are plain text you can certainly write them by hand—once you’re familiar with \(\mathrm{Bib\TeX}\)’s required syntax. Just make sure that you save it with a extension, and that your editor doesn’t surreptitiously add a or some other suffix. On Overleaf you can click on the “Files…” link at the top of the file list panel, and then on “Add blank file” to create a fresh file to work on.
Help from GUI-based editors
Export from reference library services
If you click on the Upload files button above the file list panel, you’ll notice some options: Import from Mendeley, and Import from Zotero. If you’re already using one of those reference library management services, Overleaf can now hook into the Web exporter APIs provided by those services to import the file (generated from your library) into your Overleaf project. For more information, see the Overleaf article How to link your Overleaf account to Mendeley and Zotero.
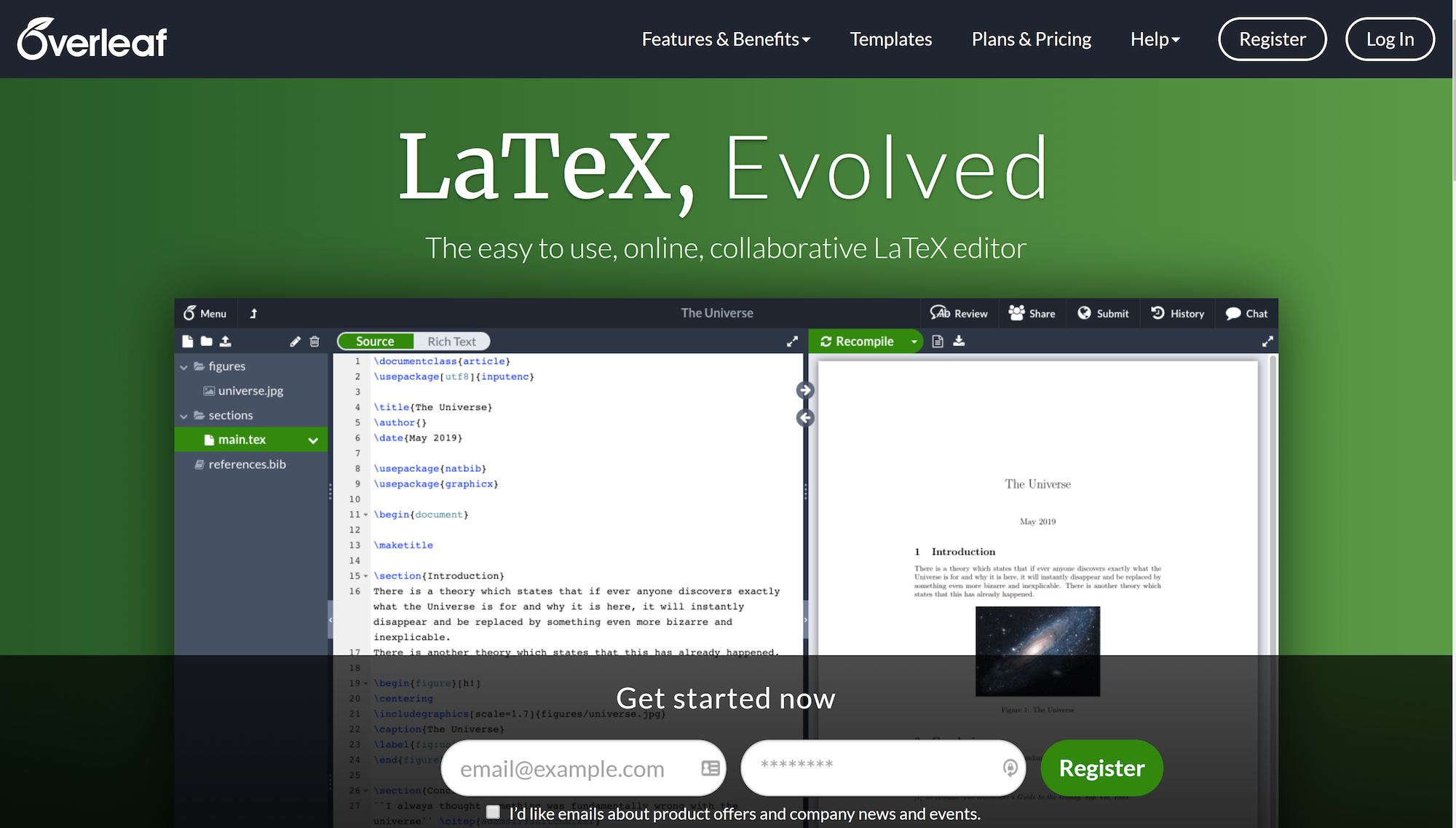
Цитирование[править]
Чтобы обозначить где-либо в документе цитату, перейдите в это место документа и вставьте , где — это уникальный идентификатор источника, уже описанный в библиографическом списке редактируемого документа. Когда LaTeX будет обрабатывать документ, по идентификатору источника будет определено, какой источник (его порядковый номер в списке библиографии) должен быть помещен на место команды . Преимущество такого подхода в том, что LaTeX сам следит за нумерацией источников, которые приводятся в ссылке. Иначе добавление нового источника в библиографический список приводило бы к изменению их нумерации в списке, а следовательно ссылки приходилось бы переделывать.
Если необходимо в ссылке указать определенную страницу, можно использовать аргумент для команды Например:
Аргумент «p. 215» помещается в те же квадратные скобки. Тильда в аргументе делает пробел между p. 215 неразрывным, чтобы номер страницы не был перенесен на следующую строку.







![Файл btx - как открыть файл .btx? [шаг-за-шагом] | filesuffix.com](https://tehnik-shop.ru/wp-content/uploads/4/5/5/4551063ab0502cdecac169d2fc1b9963.png)
Ссылка на несколько источников создается одной командой . Например:
При этом между ссылками не должно быть пробелов. В результате, в одних квадратных скобках ссылки будут несколько номеров источников.
Пакет Natbibправить
| Команды цитирования | Отображение |
|---|---|
| \citet{goossens93} | Goossens et al. (1993) |
| \citep{goossens93} | (Goossens et al., 1993) |
| \citet*{goossens93} | Goossens, Mittlebach, and Samarin (1993) |
| \citep*{goossens93} | (Goossens, Mittlebach, and Samarin, 1993) |
| \citeauthor{goossens93} | Goossens et al. |
| \citeauthor*{goossens93} | Goossens, Mittlebach, and Samarin |
| \citeyear{goossens93} | 1993 |
| \citeyearpar{goossens93} | (1993) |
| \citealt{goossens93} | Goossens et al. 1993 |
| \citealp{goossens93} | Goossens et al., 1993 |
| \citetext{priv.\ comm.} | (priv. comm.) |
Существуют различные стили цитирования. Пакет natbib, заменяющий стандартный аппарат цитирования, позволяет применять различные стили цитирования, с нумерацией, или стиль Harvard, с указанием имени автора и годом издания — (Roberts, 2003). Чтобы использовать пакет natbib, в преамбуле документа необходимо указать инструкцию
Также необходимо командой указать, какой стиль использовать для составления списка библиографии, например
| Стиль | Источник | Описание |
|---|---|---|
| plainnat | Provided | natbib-compatible version of plain |
| abbrvnat | Provided | natbib-compatible version of abbrv |
| unsrtnat | Provided | natbib-compatible version of unsrt |
| apsrev | natbib-compatible style for Physical Review journals | |
| rmpaps | natbib-compatible style for Review of Modern Physics journals | |
| IEEEtranN | natbib-compatible style for IEEE publications | |
| achemso | natbib-compatible style for American Chemical Society journals | |
| rsc | natbib-compatible style for Royal Society of Chemistry journals |
| Настройки | Описание |
|---|---|
| : : : | Круглые скобки () (default), квадратные скобки [], фигурные скобки {} или угловые скобки <> |
| цитирование нескольких источников разделенных точкой с запятой (по умолчанию) или запятой | |
| : : | стиль цитирования автор — год (по умолчанию), числовое или в верхнем индексе цитирование |
| цитирование нескольких источников расположенное в порядке появления в секции библиографии или сокращение нескольких ссылок | |
| первая цитата будет использовать ссылку с указанием всех авторов, последующие — «первый автор и др. | |
| for use with the chapterbib package. redefines \thebibliography to issue \section* instead of \chapter* | |
| keeps all the authors’ names in a citation on one line to fix some hyperref problems — causes overfull hboxes |
В командах цитирования добавление к команде буквы t означает «текстовый», буквы p — «в круглых скобках» (‘parenthesized’) По умолчанию пакет natbib сокращает число авторов в источниках с тремя и более авторами на «фамилия первого автора и другие». Добавлением звездочки (*) можно изменить это умолчание на указание всех авторов в ссылке.
Для того чтобы изменить установленные по умолчанию параметры, определяющие то, как отображаются ссылки в тексте, используется команда . Команда имеет шесть параметров:
- Символ открывающей скобки.
- Символ закрывающей скобки.
- Символ, отделяющий один источник от другого в одной ссылке.
- Аргумент если n — числовой стиль, s — числовой надстрочный стиль, любая другая буква — стиль автор-год.
- Пунктуационный знак между автором и годом (только если используются круглые скобки).
- Пунктуационный знак, используемый между годами, если множественное цитирование с одним автором и несколькими изданиями разных лет выпуска. Чтобы для этого использовать пробел применяются символы {,~}.
Например:
Как структурированы файлы BIB
Ниже приведен правильный синтаксис для формата файла BibTeX:
@entry type {citation key, AUTHOR = «Имя автора», TITLE = «Название книги», PUBLISHER = {Название издателя}, ADDRESS = {Местоположение опубликовано}}
В области «тип записи» указывается тип источника. Поддерживаются следующие: статья, книга, брошюра, конференция, вестник, сбор информации, материалы, руководство, мастер-тест, разное, phdthesis, разбирательство, techreport и неопубликованные.
Внутри поля находятся поля, которые описывают цитирование, например номер, главу, редакцию, редактор, адрес, автора, ключ, месяц, год, объем, организацию и другие.
Это то, что похоже на несколько ссылок в одном файле BIB:
@misc {lifewire_2008, url = {https://www.Go-Travels.com/bibtex-file-2619874}, journal = {Lifewire}, year = {2008}}, @book {brady_2016, place = {Место публикации не указано}, title = {Emotional insight}, издатель = {Oxford Univ Press}, автор = {Brady, Michael S}, year = {2016}}, @article {turnbull_dombrow_sirmans_2006, title = {Big House, Little House: Относительный размер и значение}, том = {34}, DOI = {10.1111 / j.1540-6229.2006.00173.x}, number = {3}, journal = {Экономика недвижимости}, автор = {Тернбулл, Джеффри К. и Dombrow, Jonathan и Sirmans, CF}, year = {2006}, pages = {439-456}}
Чтение информации из текстового файла
Для того чтобы прочитать информацию из текстового файла, необходимо описать переменную типа ifstream. После этого нужно открыть файл для чтения с помощью оператора open. Если переменную назвать F, то первые два оператора будут такими:
|
1 2 |
ifstream F; |
После открытия файла в режиме чтения из него можно считывать информацию точно так же, как и с клавиатуры, только вместо cin нужно указать имя потока, из которого будет происходить чтение данных.
Например, для чтения данных из потока F в переменную a, оператор ввода будет выглядеть так:
F>>a;
Два числа в текстовом редакторе считаются разделенными, если между ними есть хотя бы один из символов: пробел, табуляция, символ конца строки. Хорошо, когда программисту заранее известно, сколько и какие значения хранятся в текстовом файле. Однако часто известен лишь тип значений, хранящихся в файле, при этом их количество может быть различным. Для решения данной проблемы необходимо считывать значения из файла поочередно, а перед каждым считыванием проверять, достигнут ли конец файла. А поможет сделать это функция F.eof(). Здесь F — имя потока функция возвращает логическое значение: true или false, в зависимости от того достигнут ли конец файла.
Следовательно, цикл для чтения содержимого всего файла можно записать так:
|
1 2 3 4 5 6 7 8 9 |
//организуем для чтения значений из файла, выполнение//цикла прервется, когда достигнем конец файла,//в этом случае F.eof() вернет истинуwhile (!F.eof()){//чтение очередного значения из потока F в переменную a |
Для лучшего усвоения материала рассмотрим задачу.
Задача 2
В текстовом файле D:\\game\\accounts.txt хранятся вещественные числа, вывести их на экран и вычислить их количество.
Решение
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
#include «stdafx.h»#include <iostream>#include <fstream>#include <iomanip>#include <stdlib.h>using namespace std;int main(){ |
На этом относительно объемный урок по текстовым файлам закончен. В следующей статье будут рассмотрены методы манипуляции, при помощи которых в C++ обрабатываются двоичные файлы.
Встроенная система[править]
Если вы создаете только один или два документа и не планируете писать по этому предмету что-то еще, можно не тратить время на создание базы источников, которая вам больше не понадобятся. В таком случае можно ограничиться базовой и упрощенной поддержкой библиографии, уже имеющейся в самом LaTeX.
Для этого можно использовать параметр , который помещается туда, где должна быть библиография; обычно это делается в самом конце документа, перед командой .
Например:
Параметр означает, что все что находится между и это данные библиографии. в фигурных скобках показывает максимальную ширину номера ссылок в списке литературы и тем самым размер отступа слева.
Каждый источник вводится командой , где это уникальный идентификатор для данного источника, может выбираться произвольно как последовательность букв, чисел и пунктуационных символов. Можно использовать, например, фамилию первого автора, за которой следует год выхода издания, например, . То что следует за идентификатором — это само библиографическое описание источника.
Чтение информации из текстового файла
Для того чтобы прочитать информацию из текстового файла, необходимо описать переменную типа ifstream. После этого нужно открыть файл для чтения с помощью оператора open. Если переменную назвать F, то первые два оператора будут такими:
|
1 2 |
ifstream F; |
После открытия файла в режиме чтения из него можно считывать информацию точно так же, как и с клавиатуры, только вместо cin нужно указать имя потока, из которого будет происходить чтение данных.
Например, для чтения данных из потока F в переменную a, оператор ввода будет выглядеть так:
F>>a;
Два числа в текстовом редакторе считаются разделенными, если между ними есть хотя бы один из символов: пробел, табуляция, символ конца строки. Хорошо, когда программисту заранее известно, сколько и какие значения хранятся в текстовом файле. Однако часто известен лишь тип значений, хранящихся в файле, при этом их количество может быть различным. Для решения данной проблемы необходимо считывать значения из файла поочередно, а перед каждым считыванием проверять, достигнут ли конец файла. А поможет сделать это функция F.eof(). Здесь F — имя потока функция возвращает логическое значение: true или false, в зависимости от того достигнут ли конец файла.
Следовательно, цикл для чтения содержимого всего файла можно записать так:
|
1 2 3 4 5 6 7 8 9 |
//организуем для чтения значений из файла, выполнение//цикла прервется, когда достигнем конец файла,//в этом случае F.eof() вернет истинуwhile (!F.eof()){//чтение очередного значения из потока F в переменную a |


Для лучшего усвоения материала рассмотрим задачу.
Задача 2
В текстовом файле D:\\game\\accounts.txt хранятся вещественные числа, вывести их на экран и вычислить их количество.
Решение
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
#include «stdafx.h»#include <iostream>#include <fstream>#include <iomanip>#include <stdlib.h>using namespace std;int main(){ |
На этом относительно объемный урок по текстовым файлам закончен. В следующей статье будут рассмотрены методы манипуляции, при помощи которых в C++ обрабатываются двоичные файлы.
Форматы
В большинстве операционных систем текстовый файл имени относится к формату файла, который допускает только текстовое содержимое с очень небольшим форматированием (например, без полужирного шрифта или курсива ). Такие файлы можно просматривать и редактировать на текстовых терминалах или в простых текстовых редакторах . Текстовые файлы обычно имеют тип MIME , обычно с дополнительной информацией, указывающей на кодировку.
Текстовые файлы Microsoft Windows
MS-DOS и Microsoft Windows используют общий формат текстовых файлов, в котором каждая строка текста разделяется комбинацией из двух символов: возврат каретки (CR) и перевод строки (LF). Обычно последняя строка текста не завершается маркером CR-LF, и многие текстовые редакторы (включая Блокнот ) не вставляют его автоматически в последнюю строку.
В операционных системах Microsoft Windows файл считается текстовым, если суффикс имени файла (« расширение имени файла ») равен . Однако многие другие суффиксы используются для текстовых файлов с особыми целями. Например, исходный код компьютерных программ обычно хранится в текстовых файлах, которые имеют суффиксы имени файла, указывающие на язык программирования, на котором написан исходный код.
Большинство текстовых файлов Microsoft Windows используют кодировку «ANSI», «OEM», «Unicode» или «UTF-8». То, что терминология Microsoft Windows называет «кодировками ANSI», обычно представляет собой однобайтовые кодировки ISO/IEC 8859 (т. е. ANSI в меню Блокнота Microsoft на самом деле является «системной кодовой страницей», не-Unicode, устаревшей кодировкой), за исключением локалей, таких как китайский , японский и корейский, для которых требуются двухбайтовые наборы символов. Кодировки ANSI традиционно использовались в качестве системных языков по умолчанию в Microsoft Windows до перехода на Unicode. Напротив, кодировки OEM, также известные как кодовые страницы DOS., были определены IBM для использования в исходной системе отображения текстового режима IBM PC. Обычно они включают в себя графические символы и символы рисования линий, распространенные в приложениях DOS. Текстовые файлы Microsoft Windows с кодировкой «Unicode» содержат текст в формате преобразования Unicode UTF-16 . Такие файлы обычно начинаются с метки порядка следования байтов ( BOM ), которая сообщает порядок следования байтов содержимого файла. Хотя UTF-8 не имеет проблем с порядком байтов, многие программы Microsoft Windows (например, Блокнот) добавляют содержимое файлов в кодировке UTF-8 к BOM , чтобы отличить кодировку UTF-8 от других 8-битных кодировок.
Текстовые файлы Unix
В Unix-подобных операционных системах формат текстовых файлов точно описан: POSIX определяет текстовый файл как файл, который содержит символы, организованные в ноль или более строк, где строки представляют собой последовательности из нуля или более символов, отличных от новой строки, плюс завершающий символ новой строки. символ, обычно LF.
Кроме того, POSIX определяетфайл для печати в виде текстового файла, символы которого можно распечатать, а также пробелы или символы возврата в соответствии с региональными правилами. Это исключает большинство управляющих символов, которые не печатаются.
Текстовые файлы Apple Macintosh
До появления macOS классическая система Mac OS считала содержимое файла (форк данных) текстовым файлом, если его форк ресурсов указывал, что тип файла был «ТЕКСТ». Строки классических текстовых файлов Mac OS заканчиваются символами CR .
Будучи Unix-подобной системой, macOS использует формат Unix для текстовых файлов. Унифицированный идентификатор типа (UTI), используемый для текстовых файлов в macOS, называется «public.plain-text»; дополнительные, более конкретные UTI: «public.utf8-plain-text» для текста в кодировке utf-8, «public.utf16-external-plain-text» и «public.utf16-plain-text» для utf-16- закодированный текст и «com.apple.traditional-mac-plain-text» для классических текстовых файлов Mac OS.