
Введение
Регулярные выражения используются для сжатого описания некоторого
множества строк с помощью шаблонов, без необходимости перечисления
всех элементов этого множества или явного написания функции для проверки.
Большинство символов соответствуют сами себе («a» соответствует «a» и т. д.).
Исключения из этого правила называются метасимволами: .
Термин «Регулярные выражения» является переводом с английского словосочетания «Regular expressions».
Перевод не очень точно отражает смысл, правильнее было бы «шаблонные выражения».
Регулярное выражение, или коротко «регулярка», состоит из обычных символов и специальных командных последовательностей.
Например, задаёт любую цифру, а — задает любую последовательность из одной или более цифр.
Работа с регулярками реализована во всех современных языках программирования.
Однако существует несколько «диалектов», поэтому функционал регулярных выражений может различаться от языка к языку.
В некоторых языках программирования регулярками пользоваться очень удобно (например, в питоне), в некоторых — не слишком (например, в C++).
Примеры регулярных выражений
| Регулярка | Её смысл |
|---|---|
| В точности текст «simple text» | |
| Последовательности из 5 цифр означает любую цифру — ровно 5 раз |
|
| Даты в формате ДД/ММ/ГГГГ (и прочие куски, на них похожие, например, 98/76/5432) | |
| «Слова» в точности из трёх букв/цифр означает границу слова (с одной стороны буква/цифра, а с другой — нет) — любая буква/цифра, — ровно три раза |
|
| Целое число, например, 7, +17, -42, 0013 (возможны ведущие нули) — либо -, либо +, либо пусто — последовательность из 1 или более цифр |
|
| Действительное число, возможно в экспоненциальной записиНапример, 0.2, +5.45, -.4, 6e23, -3.17E-14. См. ниже картинку. |
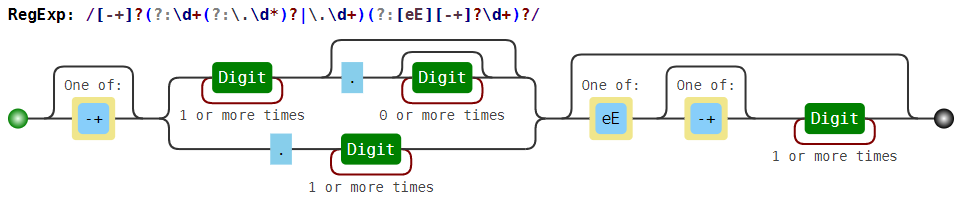
Сила и ответственность
Регулярные выражения, или коротко, регулярки — это очень мощный инструмент.
Но использовать их следует с умом и осторожностью, и только там, где они действительно приносят пользу, а не вред.
Во-первых, плохо написанные регулярные выражения работают медленно.
Во-вторых, их зачастую очень сложно читать, особенно если регулярка написана не лично тобой пять минут назад.
В-третьих, очень часто даже небольшое изменение задачи (того, что требуется найти) приводит к значительному изменению выражения.
Поэтому про регулярки часто говорят, что это write only code (код, который только пишут с нуля, но не читают и не правят).
А также шутят: Некоторые люди, когда сталкиваются с проблемой, думают «Я знаю, я решу её с помощью регулярных выражений.» Теперь у них две проблемы.
История NGL
Фраза «не буду лгать» или «Я не собираюсь лгать» возникла где-то в последние 100 лет. Его всегда использовали для обозначения честности или уязвимости, хотя часто его называют пустым разговорным выражением. Другими словами, люди часто говорят «не буду лгать» до или после мнений, которые на самом деле не являются глубокими, осуждающими или уязвимыми.
Кажется, что «не собираюсь лгать» превратилось в NGL где-то в 2009 или 2010 году. Именно тогда аббревиатура была впервые добавлена в Городской словарь, и примерно в то же время это слово начало набирать обороты в Google Trends.
Сейчас NGL находится на пике популярности в Google Trends, а это значит, что больше людей ищут это слово в Интернете, чем когда-либо прежде. Похоже, что NGL набирает популярность на таких сайтах, как Reddit и Twitter, вероятно, из-за недавнего мема «Они заставили нас в первой половине, не собираюсь лгать», который был запущен Аполлосом Хестером.
*args и **kwargs
Прежде чем завершить, поговорим про еще одну важную тему, а именно про так называемые *args (сокращение от arguments) и **kwargs (keyword arguments).
Они позволяют передавать функции различное количество позиционных (*args) или именованных (**kwargs) аргументов.
Рассмотрим на примере. Начнем с *args.
*args
Предположим, что у нас есть простая функция, которая принимает два числа и считает среднее арифметическое.
|
1 |
# объявим функцию defmean(a,b) return(a+b)2 mean(1,2) |
| 1 | 1.5 |
Все отлично работает, но мы не можем передать этой функции больше двух чисел. Возможным решением станет функция, которая изначально принимает список в качестве аргумента.
|
1 |
# объявим функцию, которой нужно передать список defmean(list_) # зададим переменную для суммы, total= # в цикле сложим все числа из списка foriinlist_ total+=i # и разделим на количество элементов returntotallen(list_) |
|
1 |
# создадим список list_=1,2,3,4 mean(list_) |
| 1 | 2.5 |
Все опять же работает, но нам каждый раз нужно создавать список. При попытке передать отдельные числа функция выдаст ошибку.
| 1 | mean(1,2) |
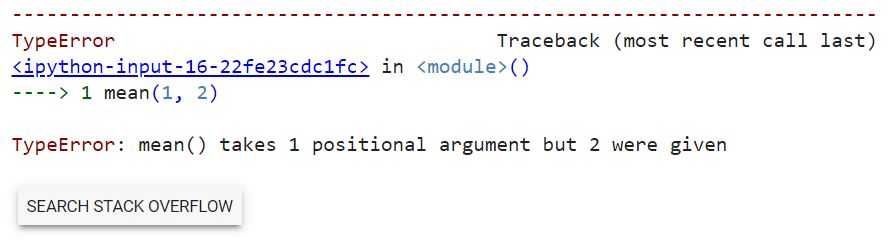
*args позволяет передавать функции произвольное количество отдельных чисел.
|
1 |
# объявим функцию с *args defmean(*nums) total= foriinnums total+=i returntotallen(nums) |
| 1 | mean(1,2,3,4) |
| 1 | 2.5 |
Как вы видите, главным элементом здесь является оператор распаковки * (unpacking operator). Он принимает все передаваемые в функцию числа и формирует из них кортеж.
Затем мы проходимся по элементам этого кортежа, рассчитываем их сумму и делим на количество элементов. Использовать слово args не обязательно, мы назвали наш позиционный аргумент nums.
Если мы по какой-то причине захотим передать функции список, мы можем это сделать.
|
1 |
# передадим в функцию список mean(*list_) |
| 1 | 2.5 |
В этом случае мы передаем название списка со звездочкой *.
Для того чтобы продемонстрировать преобразование чисел в кортеж, напишем вот такую несложную функцию.
|
1 |
deftest_type(*nums) print(nums,type(nums)) |
| 1 | test_type(1,2,3,4) |
| 1 | (1, 2, 3, 4) <class ‘tuple’> |
**kwargs
При использовании **kwargs происходит почти то же самое за тем исключением, что мы распаковываем именованные, а не позиционные аргументы. И распаковываем их в словарь, а не в список. Сразу посмотрим на примере.
|
1 |
deff(**kwargs) returnkwargs.items() |
|
1 |
# оператор ** примет произвольное количество именованных аргументов f(a=1,b=2) |
| 1 | dict_items() |
Приведем более сложный пример. Напишем функцию, которая на вход примет произвольное количество чисел (позиционный аргумент), преобразует в кортеж (*args) и рассчитает (mean) и (standard deviation).
Для каждой из метрик мы дополнительно создадим именованный параметр, который определит выводить эту метрику или нет. Параметры мы передадим через **kwargs. Внутри функции из них будет сформирован словарь.
|
1 |
# nums функция преобразует в кортеж, params — в словарь defsimple_stats(*nums,**params) # если ключ ‘mean’ есть в словаре params и его значение == True if’mean’inparams andparams’mean’==True # рассчитаем среднее арифметическое кортежа nums и округлим # \t — это символ табуляции print(f’mean: \t{np.round(np.mean(nums), 3)}’) # если ключ ‘std’ есть в словаре params и его значение == True if’std’inparams andparams’std’==True # рассчитаем СКО кортежа nums и округлим print(f’std: \t{np.round(np.std(nums), 3)}’) |
Вызовем функцию simple_stats() и передадим ей числа и именованные аргументы.
| 1 | simple_stats(5,10,15,20,mean=True,std=True) |
|
1 |
mean: 12.5 std: 5.59 |
Если для одного из параметров задать значение False, функция не выведет соответствующую метрику.
| 1 | simple_stats(5,10,15,20,mean=True,std=False) |
| 1 | mean: 12.5 |
Для того чтобы передать параметры списком и словарем, нам нужно использовать операторы распаковки
* и
** соответственно.
|
1 |
list_=5,10,15,20 settings={‘mean’True,’std’True} simple_stats(*list_,**settings) |
|
1 |
mean: 12.5 std: 5.59 |
Количество именованных аргументов в **kwargs может быть любым. Ничто не мешает нам добавить еще один параметр.
|
1 |
# добавим параметр median simple_stats(5,10,15,20,mean=True,std=True,median=True) |
|
1 |
mean: 12.5 std: 5.59 |
Впрочем, для того чтобы это имело смысл, такой параметр должен быть прописан внутри функции.
В заключение скажу, что все приведенные выше примеры являются учебными и без *args и **kwargs здесь конечно можно обойтись. На практике, они применяются в более сложных конструкциях, например, в так называемых декораторах, однако эта тема выходит за рамки сегодняшнего занятия.
Затухание светового излучения
Затухание определяет величину ослабления оптической мощности лазерного луча в децибелах на км (дБ/км) при прохождении по оптоволокну. Несмотря на высокий уровень технологий, используемых при изготовлении оптоволокна, оптическое волокно не лишено дефектов, приводящих к ослаблению передаваемого сигнала. Основными причинами, вызывающими затухание сигнала в оптоволокне, являются: поглощение и рассеивание, связанные с неоднородностью оптического материала из-за различного рода примесей, а также потери на микроизгибах оптического волокна. Зависимость значения затухания от величины волны (окна прозрачности) показана на ниже.
Строковые методы, поиск и замена
Следующие методы работают с регулярными выражениями из строк.
Все методы, кроме replace, можно вызывать как с объектами типа regexp в аргументах, так и со строками, которые автоматом преобразуются в объекты RegExp.
Так что вызовы эквивалентны:
var i = str.search(/\s/)
var i = str.search("\\s")
При использовании кавычек нужно дублировать \ и нет возможности указать флаги. Если регулярное выражение уже задано строкой, то бывает удобна и полная форма
var regText = "\\s" var i = str.search(new RegExp(regText, "g"))
Возвращает индекс регулярного выражения в строке, или -1.
Если Вы хотите знать, подходит ли строка под регулярное выражение, используйте метод (аналогично RegExp-методы ). Чтобы получить больше информации, используйте более медленный метод (аналогичный методу ).
Этот пример выводит сообщение, в зависимости от того, подходит ли строка под регулярное выражение.
function testinput(re, str){
if (str.search(re) != -1)
midstring = " contains ";
else
midstring = " does not contain ";
document.write (str + midstring + re.source);
}
Если в regexp нет флага , то возвращает тот же результат, что .
Если в regexp есть флаг , то возвращает массив со всеми совпадениями.
Чтобы просто узнать, подходит ли строка под регулярное выражение , используйте .
Если Вы хотите получить первый результат — попробуйте r.
В следующем примере используется, чтобы найти «Chapter», за которой следует 1 или более цифр, а затем цифры, разделенные точкой. В регулярном выражении есть флаг , так что регистр будет игнорироваться.
str = "For more information, see Chapter 3.4.5.1"; re = /chapter (\d+(\.\d)*)/i; found = str.match(re); alert(found);
Скрипт выдаст массив из совпадений:
- Chapter 3.4.5.1 — полностью совпавшая строка
- 3.4.5.1 — первая скобка
- .1 — внутренняя скобка
Следующий пример демонстрирует использование флагов глобального и регистронезависимого поиска с . Будут найдены все буквы от А до Е и от а до е, каждая — в отдельном элементе массива.
var str = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; var regexp = //gi; var matches = str.match(regexp); document.write(matches); // matches =
Метод replace может заменять вхождения регулярного выражения не только на строку, но и на результат выполнения функции. Его полный синтаксис — такой:
var newString = str.replace(regexp/substr, newSubStr/function)
- Объект RegExp. Его вхождения будут заменены на значение, которое вернет параметр номер 2
- Строка, которая будет заменена на .
- Строка, которая заменяет подстроку из аргумента номер 1.
- Функция, которая может быть вызвана для генерации новой подстроки (чтобы подставить ее вместо подстроки, полученной из аргумента 1).
Метод не меняет строку, на которой вызван, а просто возвращает новую, измененную строку.
Чтобы осуществить глобальную замену, включите в регулярное выражение флаг .
Если первый аргумент — строка, то она не преобразуется в регулярное выражение, так что, например,
var ab = "a b".replace("\\s","..") // = "a b"
Вызов replace оставил строку без изменения, т.к искал не регулярное выражение , а строку «\s».
В строке замены могут быть такие спецсимволы:
| Pattern | Inserts |
| Вставляет «$». | |
| Вставляет найденную подстроку. | |
| Вставляет часть строки, которая предшествует найденному вхождению. | |
| Вставляет часть строки, которая идет после найденного вхождения. | |
| or | Где или — десятичные цифры, вставляет подстроку вхождения, запомненную -й вложенной скобкой, если первый аргумент — объект RegExp. |
Если Вы указываете вторым параметром функцию, то она выполняется при каждом совпадении.
В функции можно динамически генерировать и возвращать строку подстановки.
Первый параметр функции — найденная подстрока. Если первым аргументом является объект , то следующие параметров содержат совпадения из вложенных скобок. Последние два параметра — позиция в строке, на которой произошло совпадение и сама строка.
Например, следующий вызов возвратит XXzzzz — XX , zzzz.
function replacer(str, p1, p2, offset, s)
{
return str + " - " + p1 + " , " + p2;
}
var newString = "XXzzzz".replace(/(X*)(z*)/, replacer)
Как видите, тут две скобки в регулярном выражении, и потому в функции два параметра , .
Если бы были три скобки, то в функцию пришлось бы добавить параметр .









Следующая функция заменяет слова типа на :
function styleHyphenFormat(propertyName)
{
function upperToHyphenLower(match)
{
return '-' + match.toLowerCase();
}
return propertyName.replace(//, upperToHyphenLower);
}
Распространение света в оптоволокне
Распространение луча света в оптическом волокне происходит по закону Снелла-Декарта. Часть света вводится через полный приемный конус оптоволокна.
Полный приемный конус оптического волокна определяется как
Преломление
Явление преломления выражается в изменении угла прохождения луча света через границу двух сред. Если , то луч полностью преломляется и выходит из сердцевины.
Отражение
Отражение является изменением направления светового луча на границе между двумя средами. В этом случае, световой луч возвращается в сердцевину, из которой он произошел.Если , то луч отражается и остается в сердцевине.
Принцип распространения
Лучи видимой области спектра входит в оптоволокно под разными углами и идут разными путями. Луч, вошедший в центр сердцевины под малым углом пойдёт прямо и по центру волокна. Луч вошедший под большим углом или около края сердечника пойдёт по ломаной и будет проходить по оптоволокну более медленно. Каждый путь, следуя из данного угла и точки паления даст начало моде. Поскольку моды перемещаются вдоль волокна, каждая из них до некоторой степени ослабляется.
Профиль показателя преломления различных типов оптических волокон:слева вверху — одномодовое волокно;слева внизу — многомодовое ступенчатое волокно;справа — градиентное волокно с параболическим профилем]]
Статичные регэкспы
В некоторых реализациях javascript регэкспы, заданные коротким синтаксисом /…/ — статичны. То есть, такой объект создается один раз в некоторых реализациях JS, например в Firefox. В Chrome все ок.
function f() {
// при многократных заходах в функцию объект один и тот же
var re = /lalala/
}
По стандарту эта возможность разрешена ES3, но запрещена ES5.
Из-за того, что при глобальном поиске меняется, а сам объект регэкспа статичен, первый поиск увеличивает , а последующие — продолжают искать со старого , т.е. могут возвращать не все результаты.
При поиске всех совпадений в цикле проблем не возникает, т.к. последняя итерация (неудачная) обнуляет .
Рекомендуемый этикет для использования веб-и текстового жаргона
Пользуясь здравым смыслом и зная, кто ваша аудитория поможет вам выбрать, как использовать жаргон в своих сообщениях. Если вы хорошо знаете людей, и это личное и неформальное общение, тогда абсолютно используйте аббревиатуру жаргона. С другой стороны, если вы только начинаете дружбу или профессиональные отношения с другим человеком, тогда это хорошая идея, чтобы избежать сокращений, пока вы не разработали отношения отношений.
Если обмен сообщениями находится в профессиональном контексте на работе, с управлением вашей компанией или с клиентом или поставщиком за пределами вашей компании, тогда вообще избегайте аббревиатур. Использование полного написания слов показывает профессионализм и вежливость.
Использование PMSL Вместо ROFL или LOL
Единственная разница между использованием PMSL или американскими эквивалентами ROFL / LOL / LMAO — это вопрос культурного вкуса. Вы бы использовали PMSL, если считаете, что ваши читатели в основном из Великобритании или других частей Содружества, которые говорят на неамериканском английском языке. Вы должны использовать ROFL или LOL или LMAO, когда вы ожидаете, что ваши читатели будут из Америки.
Выражение PMSL, как и многие другие онлайн-выражения и веб-жаргон, является частью культуры онлайн-разговоров и является способом создания культурной самобытности посредством языка и игривой беседы.
Пример использования всех основных функций
import re
match = re.search(r'\d\d\D\d\d', r'Телефон 123-12-12')
print(match.group(0) if match else 'Not found')
# -> 23-12
match = re.search(r'\d\d\D\d\d', r'Телефон 1231212')
print(match.group(0) if match else 'Not found')
# -> Not found
match = re.fullmatch(r'\d\d\D\d\d', r'12-12')
print('YES' if match else 'NO')
# -> YES
match = re.fullmatch(r'\d\d\D\d\d', r'Т. 12-12')
print('YES' if match else 'NO')
# -> NO
print(re.split(r'\W+', 'Где, скажите мне, мои очки??!'))
# ->
print(re.findall(r'\d\d\.\d\d\.\d{4}',
r'Эта строка написана 19.01.2018, а могла бы и 01.09.2017'))
# ->
for m in re.finditer(r'\d\d\.\d\d\.\d{4}', r'Эта строка написана 19.01.2018, а могла бы и 01.09.2017'):
print('Дата', m.group(0), 'начинается с позиции', m.start())
# -> Дата 19.01.2018 начинается с позиции 20
# -> Дата 01.09.2017 начинается с позиции 45
print(re.sub(r'\d\d\.\d\d\.\d{4}',
r'DD.MM.YYYY',
r'Эта строка написана 19.01.2018, а могла бы и 01.09.2017'))
# -> Эта строка написана DD.MM.YYYY, а могла бы и DD.MM.YYYY
Тонкости экранирования в питоне ()
Так как символ в питоновских строках также необходимо экранировать, то в результате в шаблонах могут возникать конструкции вида .
Первый слеш означает, что следующий за ним символ нужно оставить «как есть». Третий также.
В результате с точки зрения питона означает просто два слеша .
Теперь с точки зрения движка регулярных выражений, первый слеш экранирует второй.
Тем самым как шаблон для регулярки означает просто текст .
Для того, чтобы не было таких нагромождений слешей, перед открывающей кавычкой нужно поставить символ , что скажет питону «не рассматривай \ как экранирующий символ (кроме случаев экранирования открывающей кавычки)».
Соответственно можно будет писать .
Использование дополнительных флагов в питоне
| Константа | Её смысл |
|---|---|
| По умолчанию , , , , , , , соответствуют все юникодные символы с соответствующим качеством. Например, соответствуют не только арабские цифры, но и вот такие: ٠١٢٣٤٥٦٧٨٩. ускоряет работу, если все соответствия лежат внутри ASCII. | |
| Не различать заглавные и маленькие буквы. Работает медленнее, но иногда удобно | |
| Специальные символы и соответствуют началу и концу каждой строки | |
| По умолчанию символ конца строки не подходит под точку. С этим флагом точка — вообще любой символ |
Шаблоны, соответствующие не конкретному тексту, а позиции
Отдельные части регулярного выражения могут соответствовать не части текста, а позиции в этом тексте.
То есть такому шаблону соответствует не подстрока, а некоторая позиция в тексте, как бы «между» буквами.
Простые шаблоны, соответствующие позиции
всем текстомстрочкой текста
| Шаблон | Описание | Пример | Подходящие строки |
|---|---|---|---|
^ |
Начало всего текста или начало строчки текста, если |
^Привет |
|
$ |
Конец всего текста или конец строчки текста, если |
Будь здоров!$ |
|
\A |
Строго начало всего текста | ||
\Z |
Строго конец всего текста | ||
\b |
Начало или конец слова (слева пусто или не-цифро-буква, а справа цифро-буквы, либо наоборот) |
\bвал |
вал, перевал |
\B |
Не граница слова (либо и слева, и справа цифро-буквы, либо и слева, и справа НЕ цифро-буквы) |
\Bвал |
перевал, вал |
Это, конечно, не самая вежливая аббревиатура для использования онлайн или в тексте
FWM означает
F *** Со мной.
Эти звездочки могут быть заполнены оставшимися буквами, необходимыми для написания F-слова. Вы были предупреждены!
Значение FWM
В некоторых случаях FWM может иметь скорее отрицательную интерпретацию, чем положительную или нейтральную. Например, это может быть синонимом фразы «связывайся со мной».
Как используется FWM
Люди склонны использовать FWM для описания своих отношений и взаимодействий с друзьями, романтическими партнерами и другими связями, которые они имеют в своей жизни. Сам факт, что он содержит F-слово, делает его особенно привлекательным акронимом для описания романтических/сексуальных отношений.
Подростки и молодые люди гораздо чаще используют аббревиатуру, потому что это может заставить их чувствовать себя жестче и увереннее в своем социальном статусе. Они могут использовать это, чтобы выразить эмоции, установить границы, заявить, кто «на их стороне», так сказать, или даже заявить, что они будут и не будут терпеть от других людей.
Примеры использования FWM
Пример 1
“Если ты на моей странице, но никогда не знаешь, значит, ты не настоящий друг”
Пример 2
“Почему ты даже пытаешься fwm, когда ты никогда не возвращаешь мои тексты”
Второй пример выше напоминает текст, предназначенный для кого-то, кто может играть в игры только для своей выгоды – возможно, по романтическим/сексуальным причинам. Контекст этого конкретного сообщения предполагает, что FWM можно интерпретировать как «возьми меня» в романтическом/сексуальном смысле.
Пример 3
“Не надо, если ты просто уйдешь”
Третий пример, приведенный выше, можно использовать в сообщениях социальных сетей или текстовых сообщениях, но здесь важен защитный тон. В этом случае FWM, скорее всего, означает «связываться со мной» в негативном смысле.
Как решить, следует ли использовать FWM онлайн или в текстовых сообщениях
FWM – это одна из тех аббревиатур, у которой есть свой тип толпы – подростки и молодые люди, которым нужно грубое и жесткое повышение эго. Но независимо от вашего возраста и собственного имиджа/социального статуса, если вы считаете, что есть причина использовать его самостоятельно в Интернете или в текстовом сообщении, вы можете попробовать задать себе следующие вопросы, чтобы определить, стоит ли их использовать в вашем собственном онлайн/текстовом сообщении. Vocab.
- Собираюсь ли я обидеть или неуважительно относиться к кому-либо? Если да, избегайте его использования, чтобы уберечь себя от конфликта и сожалеть о том, что вы можете столкнуться позже.
- Пытаюсь ли я направить свои негативные эмоции о своих отношениях в гневное сообщение? Существуют гораздо более полезные и менее рискованные способы выпустить пар, не оскорбляя и не злите других, сидя за экраном компьютера или устройства.
- Пытаюсь ли я избежать необходимости напрямую решать проблему с конкретным человеком или людьми в моей жизни? Если да, то, что вы заявляете о том, что вы делаете/не хотите от них, или отказываетесь от участия, не исправит Это.
Похожие аббревиатуры
Все, рассмотренные ниже сокращения, используются в письмах по одному принципу: размещается в графе RE, или FW. Но разные фразы имеют неодинаковую смысловую нагрузку.
ATN (от англ
attention, расшифровывается, как “внимание”) и подразумевает, что информация не просто должна быть замечена, во время пролистывания новых писем, а ей стоит уделить время. Понятно, что эта аббревиатура похожа по значению с FYI
Но письмо со значком ATN, следует ответить для того, чтобы уведомить адресанта в ознакомлении с полученной информацией.
TY (от англ. thank you). Аббревиатура не требует особых объяснений. Письмо с такой отметкой отправляется в ответ, означает “спасибо”.
YNK (англ. You never know), переводится как “никогда не знаешь“. Часто используется в неформальных переписках. Наиболее используемыми считаются также LOL – “laughing out loud”, дословно это переводится, как “смех вслух”, а используется, чтобы передать смех.
IMHO – “in my hummble opinion” – по моему скромному мнению.
BTW – “by the way” – кстати.
LOL — очень популярна аббревиатура (на самом деле ничего не имеет общего с похожим словом в русском языке), которая выражает эмоции типа смех или легкую иронию; хоть это и западная аббревиатура, в русскоязычном интернете также очень популярна не только на форумах;
OMG! – “oh my god!” – о, Боже!
SY – “see you” – увидимся, и многие другие.
Использование аббревиатуры FYI стало настолько популярным за рубежом, что этот факт даже нашёл отражение в фольклоре. теперь и Вы знаете что значит fyi и легко сможете отреагировать правильным образом.
Вводим слова
Чтобы игрок мог вводить слова, добавим обработчик события «keydown» — оно сработает в момент нажатия клавиши. Работать алгоритм будет так:
- Если все попытки угадать слово истрачены, обработчик тут же завершается, потому что вводить новые символы просто некуда.
- Если нажата клавиша Backspace — вызывается функция удаления последнего символа.
- Если нажат Enter — вызывается функция проверки слова, угадали мы или нет.
- А если нажата какая-то другая клавиша, то алгоритм проверит, попадают ли введённые символы в английский алфавит (потому что у нас сейчас версия для английского языка). Если попадают — вызывается функция добавления символа в клетку. Здесь нам пригодятся регулярные выражения, с которыми мы уже работали в других проектах.
Запишем это на JavaScript:
Если обновить страницу с проектом в браузере, то при попытке ввода получим ошибку — всё потому, что у нас нет ни одной функции, на которые мы здесь ссылаемся. Исправим это и добавим их все по очереди.
Поиск всех совпадений с группами: matchAll
является новым, может потребоваться полифил
Метод не поддерживается в старых браузерах.
Может потребоваться полифил, например https://github.com/ljharb/String.prototype.matchAll.
При поиске всех совпадений (флаг ) метод не возвращает скобочные группы.
Например, попробуем найти все теги в строке:
Результат – массив совпадений, но без деталей о каждом. Но на практике скобочные группы тоже часто нужны.
Для того, чтобы их получать, мы можем использовать метод .
Он был добавлен в язык JavaScript гораздо позже чем , как его «новая и улучшенная» версия.
Он, как и , ищет совпадения, но у него есть три отличия:
- Он возвращает не массив, а перебираемый объект.
- При поиске с флагом , он возвращает каждое совпадение в виде массива со скобочными группами.
- Если совпадений нет, он возвращает не , а просто пустой перебираемый объект.
Например:
Как видите, первое отличие – очень важное, это демонстрирует строка. Мы не можем получить совпадение как , так как этот объект не является псевдомассивом
Его можно превратить в настоящий массив при помощи . Более подробно о псевдомассивах и перебираемых объектов мы говорили в главе Перебираемые объекты.
В явном преобразовании через нет необходимости, если мы перебираем результаты в цикле, вот так:
…Или используем деструктуризацию:
Каждое совпадение, возвращаемое , имеет тот же вид, что и при без флага : это массив с дополнительными свойствами (позиция совпадения) и (исходный текст):
Почему результат – перебираемый объект, а не обычный массив?
Зачем так сделано? Причина проста – для оптимизации.
При вызове движок JavaScript возвращает перебираемый объект, в котором ещё нет результатов. Поиск осуществляется по мере того, как мы запрашиваем результаты, например, в цикле.



Таким образом, будет найдено ровно столько результатов, сколько нам нужно.
Например, всего в тексте может быть 100 совпадений, а в цикле после 5-го результата мы поняли, что нам их достаточно и сделали . Тогда движок не будет тратить время на поиск остальных 95.
Аббревиатуры Web и Texting: капитализация и пунктуация
При использовании сокращений текстовых сообщений и жаргонов чата капитализация не вызывает беспокойства. Вы можете использовать все прописные буквы (например, ROFL) или все строчные буквы (например, rofl), и значение идентично. Избегайте ввода всего предложения в верхнем регистре, хотя это означает, что крик в онлайн-разговоре.
- Правильная пунктуация аналогично не касается с большинством аббревиатур текстовых сообщений. Например, аббревиатура для «Слишком длинная, не читаемая» может быть сокращена как TL, DR или TLDR. Оба являются приемлемым форматом, с или без пунктуации.
- Никогда не используйте периоды (точки) между буквами жаргона. Это победит цель ускорения ввода большого пальца. Например, ROFL никогда не будет записан R.O.F.L., и TTYL никогда не будет записан T.T.Y.L.
Как оценивают соблюдение ESG-принципов
Бизнес, который претендует на хорошую ESG-оценку, должен соответствовать стандартам развития в трех категориях: социальной, управленческой и экологической.
Экологические принципы определяют, насколько компания заботится об окружающей среде и как пытается сократить ущерб, который наносится экологии.
Например, бренд обуви Timberland сотрудничает с производителем шин Omni United и делает подошвы ботинок из переработанных шин.
Социальные принципы показывают отношение компании к персоналу, поставщикам, клиентам, партнерам и потребителям. Чтобы соответствовать стандартам, бизнес должен работать над качеством условий труда, следить за гендерным балансом или инвестировать в социальные проекты.
Например, американский бренд верхней одежды Patagonia не владеет фабриками, которые шьют его продукцию, поэтому не может влиять на размер зарплаты рабочих. Чтобы это исправить, в рамках программы «Честная торговля» бренд направляет часть средств с продажи продукции на фабрики, чтобы поднять зарплату сотрудников до уровня прожиточного минимума.
К 2019 году бренду Patagonia удалось поднять зарплату рабочим до прожиточного минимума на 11 из 31 фабрики
(Фото: Patagonia)
Управленческие принципы затрагивают качество управления компаниями: прозрачность отчетности, зарплаты менеджмента, здоровую обстановку в офисах, отношения с акционерами, антикоррупционные меры.
По словам Евгения Хилинского, директора управления анализа инструментов с фиксированной доходностью Газпромбанка, для устойчивого развития компания должна соблюдать баланс между всеми критериями. Но их значимость может различаться в зависимости от деятельности разных компаний. Например, для энергетики особую роль играют экологические критерии, для сектора услуг — социальные, а для финансов — управленческие.
Поиск совпадений: метод exec
Метод возвращает массив и ставит свойства регулярного выражения.
Если совпадений нет, то возвращается null.
Например,
// Найти одну d, за которой следует 1 или более b, за которыми одна d
// Запомнить найденные b и следующую за ними d
// Регистронезависимый поиск
var myRe = /d(b+)(d)/ig;
var myArray = myRe.exec("cdbBdbsbz");
В результате выполнения скрипта будут такие результаты:
| Объект | Свойство/Индекс | Описания | Пример |
| Содержимое . | |||
| Индекс совпадения (от 0) | |||
| Исходная строка. | |||
| Последние совпавшие символы | |||
| Совпадения во вложенных скобках, если есть. Число вложенных скобок не ограничено. | |||
| Индекс, с которого начинать следующий поиск. | |||
| Показывает, что был включен регистронезависимый поиск, флаг «». | |||
| Показывает, что был включен флаг «» поиска совпадений. | |||
| Показывает, был ли включен флаг многострочного поиска «». | |||
| Текст паттерна. |
Если в регулярном выражении включен флаг «», Вы можете вызывать метод много раз для поиска последовательных совпадений в той же строке. Когда Вы это делаете, поиск начинается на подстроке , с индекса . Например, вот такой скрипт:
var myRe = /ab*/g;
var str = "abbcdefabh";
while ((myArray = myRe.exec(str)) != null) {
var msg = "Found " + myArray + ". ";
msg += "Next match starts at " + myRe.lastIndex;
print(msg);
}
Этот скрипт выведет следующий текст:
Found abb. Next match starts at 3 Found ab. Next match starts at 9
В следующем примере функция выполняет поиск по input. Затем делается цикл по массиву, чтобы посмотреть, есть ли другие имена.
Предполагается, что все зарегистрированные имена находятся в массиве А:
var A = ;
function lookup(input)
{
var firstName = /\w+/i.exec(input);
if (!firstName)
{
print(input + " isn't a name!");
return;
}
var count = 0;
for (var i = 0; i < A.length; i++)
{
if (firstName.toLowerCase() == A.toLowerCase())
count++;
}
var midstring = (count == 1) ? " other has " : " others have ";
print("Thanks, " + count + midstring + "the same name!")
}
Когда использовать THNX против благодарности
Итак, теперь, когда вы знаете, что означает эта аббревиатура (плюс все ее многочисленные другие варианты), вы также должны знать, когда это так и не подходит. Вот несколько рекомендаций по использованию, если вы планируете использовать его.
Используйте THNX, когда:
- У вас дружеский, случайный разговор.
- Скорость вашего ответа имеет большее значение, чем орфография и грамматика.
- Вы знаете другого человека / людей достаточно хорошо, что вам не нужно поддерживать высокую репутацию или существенно впечатлять их.
Используйте спасибо, когда:
- У вашего разговора больше серьезного оттенка, чем случайного.
- Скорость вашего ответа не имеет значения. Например, тщательно обработанное электронное сообщение может быть лучше подходит для высказывания благодарности, чем разговор в режиме реального времени, проводимый в Facebook Messenger.
- Вы должны поблагодарить кого-то, кого вы глубоко уважаете и хотите произвести впечатление (например, работодателя, профессора, потенциального любовного интереса и т. Д.).