
Введение
Система управления базами данных (СУБД) — это тип программного обеспечения, которое взаимодействует с самой базой данных, приложениями и пользовательскими интерфейсами для получения данных и их анализа. СУБД также содержит ключевые инструменты для управления данными.Для сравнения мы выбрали наиболее часто используемых системы управления базами данных, опираясь на опросы специалистов в 2021 году
Сосредоточив внимание на их преимуществах и проблемах, связанных с реальным практическим использованием, постараемся очертить сферу рационального применения для каждой из них.Настоящая работа во многом является продолжением опубликованной ранее статьи , в которой приведён сравнительный анализ более десятка систем управления базами данных (СУБД) для информационной системы промышленного предприятия. Однако в данном случае авторы умышленно смещают фокус на самые популярные СУБД, не принимая во внимание СУБД, которые не вошли в ТОР-10, даже невзирая на их выдающиеся или уникальные технические характеристики
Популярность СУБД определялась согласно анализу результатов опроса специалистов, работающих в сфере информационных технологий, проведённого в конце 2021 года. Таким образом, основываясь на изложенных данных можно прогнозировать наиболее предпочтительные СУБД для внедрения в 2022 году.
Объектно-ориентированная СУБД
Эта СУБД предназначена для хранения и обработки объектов. Как и в ООП (объектно-ориентированном программировании), у этих объектов в СУБД есть свойства и методы. И они тоже реализуют инкапсуляцию и полиморфизм.
Главная цель применения объектно-ориентированной СУБД — облегчить жизнь разработчикам, использующим модель объектного программирования. Им не придется преобразовывать объекты в таблицы и строки со связями и обратно.
Самые известные объектно-ориентированные СУБД:
- MongoDB Realm;
- InterSystems Caché;
- ObjectStore;
- Actian NoSQL DB;
- Objectivity/DB.
Когда следует выбирать объектно-ориентированную СУБД?
Вообще-то не доводилось видеть много успешных реализаций с такими СУБД. Объектно-ориентированные базы данных обычно рекомендуется использовать при 1) высокопроизводительных манипуляциях с объектами, имеющими сложную структуру.
В то же время разработка 2) предполагает применение объектно-ориентированных языков программирования. Объектно-ориентированные БД распространены в системах реального времени, архитектуре и инженерии для 3D-моделирования, телекоммуникациях и научных продуктах, молекулярной науке и астрономии.
Когда не следует выбирать объектно-ориентированную СУБД?
Локальный кэш распределенной информации
В системе слежения за почтовыми отправлениями никогда не требуется доступ ко всей информации сразу. Это обычное явление во всех областях применения: есть вся накопленная и доступная информация, а есть та ее маленькая часть, которая актуальна на конкретный момент времени.
Ничто не мешает веб-ресурсу создать локальный образ распределенной базы данных. Например, пришел посетитель. Еще до того, как он сформулирует запрос, можно подгрузить варианты ответа.
Если есть опыт работы с посетителями из конкретной страны, то может быть известно, из каких стран ожидаются данные.
В некоторых странах система слежения загружена, в основном, локальными запросами (внутри страны), ничто не мешает оптимизировать этот момент, а внешние отправления отдать на откуп другим веб-ресурсам. В некоторых случаях необходимо не только предоставить посетителю внешнюю информацию, но и сопоставить сведения по ответу на один и тот же запрос от разных систем слежения.
Сказать, что в таком случае получится объектно-реляционная модель информации и доступа к ней в определенном смысле возможно, но для реализации этой модели потребуется представить инструмент моделирования действий компаний, работающих в области слежения, то есть развивающих свой функционал.
На какие критерии обратить внимание при выборе СУБД
Для того, чтобы правильно подобрать систему, необходимо учитывать целый комплекс критериев:
Тип проекта. Изначально ответьте себе на два вопроса – область применения проекта и его масштаб. Если СУБД нужна вам для небольшого проекта, то достаточно будет бесплатного варианта. Для подобных целей подходят и локальные системы, которые встраиваются в ПО и за его пределами не работают.
Что будем хранить. Обязательно понимать, какие базы данных сейчас используются вами. Этом могут быть таблицы, текстовые файлы, аудио и видео формат. И уже под них подбирать систему.
Объем. Существуют СУБД, способные работать с базами данных любого объёма. При этом они могут стабильно масштабироваться. Другие, наоборот, рассчитаны на ограниченный информационный массив.
Серверная или файловая. Последний вариант подходит для небольших организаций, которые оперируют незначительным объёмом данных и планируют хранить их в рамках своей компании, то есть локально. Серверная система более сложная – трёхуровневая. Обращение к ней происходит по цепочке «клиент-сервер компании-база данных».
Нагрузка. Она определяется числом одновременно подключаемых пользователей. Этот фактор нужно рассчитывать индивидуально с учётом проекта.
Масштабируемость. Обязательно учитывайте, что любой проект имеет тенденцию к развитию. Вполне возможно, что развитие пойдёт быстрыми темпами и нагрузки возрастут, поэтому система должна быть способна масштабироваться.
Безопасность. Через СУБД проходит масса данных и они должны быть максимально защищены – шифрование, многоэтапная защита от утечек и не только.
Отказоустойчивость. Под этим термином принято понимать способность СУБД восстановиться после сбоя без потери данных
Это очень важно для государственных и банковских структур.
Платная или бесплатная. Важный момент, так как платные СУБД зачастую очень дороги – лицензия на них может стоить сотни долларов
Бесплатные проекты ничуть не хуже по своим функциями, обычно они имеют открытый код и могут даже адаптироваться под ваши задачи.
Поддержка разработчиков. Многие системы предлагают пакетную поддержку системы, но она является платной. Нередко такие решения сопровождают бесплатные СБУД – скачивание и установка свободные, а вот за поддержку нужно вносить деньги.
Администрирование. Некоторые системы требуют отдельного специалиста на администрирование. Поэтому перед окончательным выборе СУБД подумайте, сможете ли вы выделить квалифицированного сотрудника под эти цели.
10 место. Neo4j
Одна из наиболее известных графовых БД, предназначенная для хранения и анализа взаимосвязанных наборов данных. Информация в базе хранится в виде узлов, отношений и описывающих их свойств. Структуру графа можно изменять в режиме реального времени.
Базу данных отличает высокая производительность и масштабируемая архитектура. Для управления данными используют язык запросов Cypher.
Рекомендуется для задач, где информацию можно представить в виде графов и важен анализ взаимосвязей между данными:
Не рекомендуется для задач, где
- структура данных фиксированная и табличная, а сами данные слабо связаны;
- запись данных преобладает над чтением и/или используются простые запросы без операторов соединения SQL;
- ожидается массовое сканирование всего объема данных без указания отправной точки поиска;
- требуется хранение большого объема текстовых или двоичных данных.
Открытые вопросы Рефлексии[править]
-
- Обоснуйте свою позицию, расскажите, что именно из услышанного вы считаете значимым. Социально-значимый эффект, практическая польза, масштабность решения, новизна и т.п. Выделите критерий, на основе которого вы выделяете какой-то контент.
Как вы планируете применять полученные в ходе интенсива знания в вашей дальнейшей работе?
-
- Опишите, как и в каких процессах, для каких целей и/или задач вы можете использовать тот или иной пример, материал или решение, с которыми вы познакомились в рамках интенсива.
Какие вопросы, рассмотренные в рамках интенсива, вы бы хотели более детально изучить в ближайшее время и почему?
PosgreSQL
Масштабируемая объектно-реляционная база данных, работающая на Linux, Windows, OSX и некоторых других системах. В PostgreSQL 10 есть такие функции, как логическая репликация, декларативное разбиение таблиц, улучшенные параллельные запросы, более безопасная аутентификация по паролю на основе SCRAM-SHA-256.
- Разработчик: PostgreSQL Global Development Group
- Написана на C
- Используется в компаниях: Apple, Cisco, Fujitsu, Skype, and IMDb
Особенности
- Поддержка табличных пространств, а также хранимых процедур, объединений, представлений и триггеров.
- Восстановление на момент времени (PITR).
- Асинхронная репликация.
Cassandra
Несмотря на то, Кассандра была создана Facebook (а также используется Twitter), вы не должны сразу написать его в качестве базы данных, которая не была бы применима к вашему бизнесу. Это хорошая смесь знакомство SQL с преимуществами NoSQL, так как он использует удобный интерфейс CQL который похож на SQL, и представляет собой смесь из колонки на основе базы данных и ключ-значение магазине. Это придает ему приятный внешний вид в то же время чрезвычайно масштабируемым и способен обрабатывать огромные объемы данных быстро (особенно при записи данных), последние два атрибута, объясняющие, почему это так эффективны при использовании социальных медиа-платформ. Существуют также настраиваемые параметры последовательности. Кассандра нашла широкое признание в финансовом и банковском отраслях, а также популярным для веб-аналитики и измерений.
Столбцовая СУБД
Столбцовая СУБД очень непохожа на реляционную: хотя так же состоит из сгруппированных в таблицы строк с атрибутами и по логической модели мало чем от нее отличается — на уровне физического хранилища имеет существенные различия.
Реляционная СУБД хранит данные построчно. То есть для считывания значения конкретного столбца приходится считывать почти всю строку — от первого до этого столбца.
Столбцовая СУБД хранит данные по столбцам. То есть столбец предстает в виде отдельной таблицы. А считывание выполняется прямо из конкретного столбца. На самом деле работает очень быстро — протестировано на нескольких реализованных хранилищах данных.
Преимущества столбцовой СУБД:
- эффективно выполняет сложные аналитические запросы для большого объема данных;
- простое и почти мгновенное реструктурирование таблиц с данными;
- существенное сжатие, которое экономит много места.
Самые известные столбцовые СУБД:
- Sybase IQ (SAP IQ);
- Vertica;
- ClickHouse;
- Google BigQuery;
- InfoBright;
- Apache Druid.
Когда следует выбирать столбцовую БД?
1) При создании хранилища данных и осуществлении выборки со сложными аналитическими вычислениями. 2) Когда количество запрашиваемых строк превышает сотни миллионов.
Когда не следует выбирать столбцовую СУБД?
1) Когда количество строк в таблице, из которой делаются запросы, меньше сотен миллионов. Здесь у столбцовой СУБД перед реляционной преимуществ будет немного.
2) Когда запросы достаточно простые и со статичными параметрами. В этом случае — учитывая специфику системы — столбцовая СУБД будет неэффективна.
Понятие базы данных
Построение статической модели важно. Это этап формирования представлений о том, что актуально в области применения и понимания, что может в ней развиваться дальше. На современном уровне знаний динамика — это дискретная последовательность статических моделей, а точнее — серии воплощений представлений в форме доступной для понимания не только автором, то есть вне его сознания, в модели, в графике, в связях, в программных описаниях
На современном уровне знаний динамика — это дискретная последовательность статических моделей, а точнее — серии воплощений представлений в форме доступной для понимания не только автором, то есть вне его сознания, в модели, в графике, в связях, в программных описаниях.
По общему мнению, «база данных — это информационная модель, позволяющая упорядоченно хранить данные о группе объектов, обладающих одинаковым набором свойств. Информация в базах хранится в упорядоченном виде».
Энциклопедическое «знание» обычно гласит: «База данных — представленная в объективной форме совокупность самостоятельных материалов (статей, расчетов, нормативных актов, судебных решений и иных подобных материалов), систематизированных таким образом, чтобы эти материалы могли быть найдены и обработаны с помощью электронной вычислительной машины».
Некоторые авторы по старинке (до того, как компьютеры стали персональными, переносными и карманными) выделяют особую когорту: настольные базы данных к которым относят все, что меньше одного терабайта, а также не имеет отношения к Oracle.
Альтернативы баз данных NoSQL
С ростом потребности организаций в манипулировании большими наборами сложных данных, некоторые из которых не имеют традиционной структуры, базы данных «NoSQL» стали более распространенными. База данных NoSQL не структурирована на основе общего дизайна столбцов / строк традиционных реляционных баз данных, а использует более гибкую модель данных. Модель варьируется в зависимости от базы данных: некоторые организуют данные по паре ключ / значение, графикам или широким столбцам.
Если вашей организации необходимо обработать большое количество данных, рассмотрите этот тип базы данных, который обычно проще настраивать, чем некоторые RDBM, и более масштабируемый. В число главных претендентов входят MongoDB, Cassandra, CouchDB и Redis.
Складирование данных
У предприятия могут быть десятки различных систем обработки транзакций. Все эти системы сложны и требуют команды разработчиков для поддержки, так что в итоге эксплуатируются практически автономно друг от друга.
Обычно от этих OLTP-систем ожидается высокая доступность и обработка транзакций с низкой задержкой, поскольку они зачастую критичны для работы бизнеса. Администраторы БД обычно крайне неохотно разрешают бизнес-аналитикам выполнять произвольные аналитические запросы на этих базах, ведь эти запросы зачастую оказываются ресурсоемкими, связаны с просмотром больших частей набора данных, что может отрицательно сказаться на производительности выполняемых в этот момент транзакций.
Склад данных, напротив, представляет собой отдельную БД, которую аналитики могут опрашивать так, как им заблагорассудится, не влияя при этом на OLTP-операции. Склад содержит предназначенную только для чтения копию данных из всех различных OLTP-систем компании. Данные извлекаются из баз OLTP (с помощью выполнения периодических дампов данных или непрерывного потока обновлений данных), преобразуются в удобный для анализа вид, очищаются и затем загружаются в склад. Процесс их помещения в склад известен под названием «извлечение — преобразование — загрузка» (extract — transform — load, ETL).
Рис. 8 – Упрощенная схема ETL в складе данных
Большим преимуществом использования отдельного склада данных, а не выполнения запросов непосредственно к OLTP-системам является то, что склады можно оптимизировать в расчете на аналитические паттерны доступа.
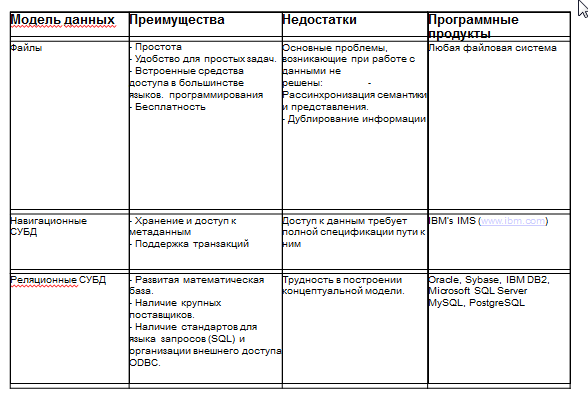
Реляционные базы данных
В последнее время большое распространение получила «реляционная модель», суть которой заключается в том, что основанная на математической теории множеств она рассматривает таблицы как отдельные множества, объединённые по определённому признаку, как показано на рисунке 1.
Рисунок 1 – Операция над таблицами (реляционная модель)
Для удобства представления и хранения система хранения данных в рамках реляционной модели обычно представляет собой совокупность таблиц, взаимосвязанных между собой определённым образом.
Таблица представляет собой плоскую двумерную сетку, которая содержит определённый тип или типы структурированных данных, например фильмы, группы крови, маршруты движения и т. д.
Если разбирать дальнейшее устройство любой таблицы, то она состоит из столбцов и строк.
Столбец таблицы представляет собой вертикальную область, выделенное свойство всех типологий, которые содержатся обычно в строках таблицы.
Строка таблицы представляет собой горизонтальную область, которая уникализирует типологию. Например, в строках таблицы могут содержаться фамилии, марки автомобилей, названия улиц и т. д.
Структурные элементы таблицы, из которых она состоит, взаимодействуют между собой, а также с другими структурными элементами других таблиц.
С ростом количества информации появилась необходимость в специальном языке, который бы оперировал данными и мог функционировать в абсолютно различающихся компьютерных системах таким образом, чтобы пользователи могли оперировать данными, составляя определённые запросы.
Отвечая на запросы времени, появился определённый язык, который получил название SQL – Structured Query Language (язык структурированных запросов), он был выпущен в 1986 году и к нынешнему времени фактически стал стандартом.
В качестве основных форм языка SQL можно назвать следующие:
-
интерактивная;
-
встроенная;
-
динамическая;
-
статическая.
Суть интерактивного SQL заключается в том, что пользователь базы данных может в интерактивном режиме использовать SQL-операторы.
Встроенный SQL позволяет интегрировать его операторы в код программы; в свою очередь, динамическая форма позволяет на лету генерировать операторы в процессе выполнения программ.
В отличие от перечисленных выше, статический представляет собой заранее определённые операторы в момент компиляции программы.
Если же говорить о достоинствах языка SQL, то среди них можно перечислить следующие:
-
переносимость между различными платформами;
-
стандартизированность;
-
поддержка компанией IBM;
-
поддержка компанией Microsoft;
-
основан на реляционных принципах;
-
высокоуровневая структура;
-
может исполнять запросы интерактивно;
-
может давать доступ к базам данных через программы;
-
предоставляет все средства языка для удобного доступа к базам данных;
-
поддержка различных архитектур;
-
поддержка бизнес-приложений;
-
наличие доступа к данным через сеть Интернет;
-
интегрированность с языком Java.
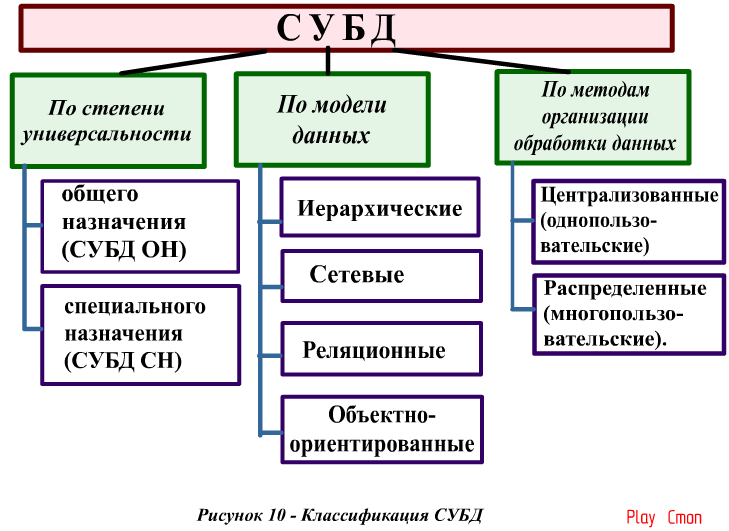
Системы управления базами данных могут работать как в качестве серверной части, то есть реализовывать архитектуру «клиент-сервер», так и в виде настольной версии, то есть СУБД, работающей локально.
Серверная система управления базами данных занимается хранением и поддержкой, а также отвечает на поступающие от клиентов запросы.
Под клиентами подразумеваются любые компьютеры или приложения, которые обращаются к базе данных, используя специальный язык обращений.
Причём если мы говорим об архитектуре «клиент-сервер», то клиент может даже находиться в одной стране, а сервер – в другой. Здесь под клиентом понимается обычный компьютер, а под сервером – специализированная машина, достаточно мощная, чтобы хранить базы и обрабатывать множество запросов.
В качестве главного отличия любой настольной СУБД от серверной можно назвать то, что она работает локально и не может обрабатывать запросы, поступающие от других клиентов.
Если перечислить основные виды известных SQL-серверов, то среди них можно назвать: Microsoft SQL Server, Oracle, MySQL, Postgresql.
В свою очередь, системой, поддерживающей SQL и являющейся настольной, можно назвать Microsoft Access.
Базы данных сервера
Серверные базы данных , такие как Microsoft SQL Server , Oracle, PostgreSQL с открытым исходным кодом и IBM DB2, предлагают организациям возможность эффективно управлять большими объемами данных таким образом, чтобы многие пользователи могли одновременно получать доступ к данным и обновлять их. Если вы можете справиться с огромным ценником, база данных на базе сервера может предоставить вам комплексное решение для управления данными.
Преимущества, достигаемые благодаря использованию серверной системы, разнообразны. Давайте посмотрим на некоторые из наиболее важных достижений:
- Гибкость. Серверные базы данных могут справиться практически с любой проблемой управления данными, с которой вы можете столкнуться. Разработчики любят эти системы, потому что они имеют дружественные к программисту интерфейсы приложений (или API), которые обеспечивают быструю разработку ориентированных на базы данных пользовательских приложений. Платформа Oracle доступна даже для нескольких операционных систем, предоставляя наркоманам Linux равное игровое поле в паре с людьми Microsoft.
- Мощная производительность. Серверные базы данных настолько мощные, насколько вы хотите. Крупные игроки могут эффективно использовать практически любую разумную аппаратную платформу, которую вы можете создать для них. Современные базы данных могут управлять несколькими высокоскоростными процессорами, кластерными серверами, высокоскоростным подключением и отказоустойчивой технологией хранения.
- Масштабируемость. Этот атрибут идет рука об руку с предыдущим. Если вы готовы предоставить необходимые аппаратные ресурсы, серверные базы данных могут корректно обрабатывать быстро растущее количество пользователей и / или данных.
СУБД временных рядов
Эта СУБД оптимизирована для хранения данных с метками времени или данных временных рядов. Данные временных рядов содержат измерения или события, которые отслеживаются, собираются или объединяются за определенный период времени.
Это данные с датчиков отслеживания движения, метрики JVM из приложений на Java, данные о рыночной торговле, сетевые данные, ответы от API, время безотказной работы процесса и т. д.

Данные хранятся с метками времени — это ключевая особенность — и индексируются и записываются так, чтобы данные этого временного ряда запрашивались намного быстрее, чем при использовании в классической реляционной БД.
Самые известные СУБД временных рядов:
- InfluxDB;
- Kdb+;
- Prometheus;
- TimescaleDB;
- QuestDB;
- AWS Timestream;
- OpenTSDB;
- GridDB.
Когда следует выбирать СУБД временных рядов?
Основная область применения таких СУБД — мониторинг, обработка телеметрии и финансовые системы.
Когда не следует выбирать СУБД временных рядов?
PostgreSQL
PostgreSQL – система управления базами данных объектно-реляционного типа.
Плюсы:
- Индексирование географических и геометрических объектов;
- Функция наследования;
- Надёжность механизмов транзакций;
- Дополнительная система расширения языков программирования;
- Автоматически встроенная поддержка слабо структурированных данных;
- Высокопроизводительность репликаций;
- Огромный набор встроенных типов данных.
Минусы:
С системой postgresql часто возникают трудности с обновлением, что, в принципе, не является важной проблемой, но причиняет всё-таки дополнительные трудности
Стабильность и надёжность
Особенность разработки SQLite также в том, что тестами покрыто 100% исходного кода. Это значит, что в нём протестированы каждая функция, обработчик и класс, причём на всех уровнях — от юнита до всей системы.
Тестов в разработке SQLite настолько много, что объём кода для тестов давно превысил объём самого SQLite. А всё для того, чтобы база данных работала даже в самых сложных условиях, например:
- при нехватке памяти;
- при неправильно сформированных запросах;
- при внезапном отключении питания;
- при одновременном доступе к базе миллиона пользователей;
- на слабом железе;
- при повреждениях оперативной памяти во время выполнения запроса.
По этой причине SQLite часто используется там, где нужна максимальная надёжность и работа в неопределённых условиях.
Документные СУБД
Документные или документно-ориентированные СУБД — это одна из наиболее популярных разновидностей NoSQL СУБД, где основной единицей логической модели данных является документ — структурированный текст, с определенным синтаксисом.
Иногда встречаются мнения что модель данных в документных БД похожа на модель данных в объектно-ориентированных базах данных. В этом есть доля правды, единственная реальная разница между ними заключается в том, что базы данных документов только сохраняют состояние, но не поведение.
Так же, само название «документо-ориентированная» подчас вводит в заблуждение, и мне встречались коллеги, которые считали, что это база для систем документооборота. Нет, это не так.
Интересно, что документные СУБД развиваются достаточно активно, и сейчас некоторые из них, в том числе, поддерживают проверку схемы.
Известными представителями таких СУБД являются CouchDB, MongoDB, Amazon DocumentDB.
Когда выбирать документную СУБД
Если нужно хранить объекты в одной сущности, но с разной структурой. Если нужно хранит структуры, включая объекты, списки и словари, особенно в формате близкому к JSON.
На самом деле область применения документных СУБД очень широкая. Их можно использовать как компактную базу данных для отдельно взятого микро-сервиса, так и для вполне масштабных решений, в качестве хранилища состояний чего-либо.
Когда не выбирать документную СУБД
Не самое лучшее решение для реализации транзакционная модели, и точно не лучший вариант для формирования отчетности.